理解MySQL——索引與優(yōu)化
寫(xiě)在前面:索引對(duì)查詢(xún)的速度有著至關(guān)重要的影響,理解索引也是進(jìn)行數(shù)據(jù)庫(kù)性能調(diào)優(yōu)的起點(diǎn)。考慮如下情況,假設(shè)數(shù)據(jù)庫(kù)中一個(gè)表有10^6條記錄,DBMS的頁(yè)面大小為4K,并存儲(chǔ)100條記錄。如果沒(méi)有索引,查詢(xún)將對(duì)整個(gè)表進(jìn)行掃描,最壞的情況下,如果所有數(shù)據(jù)頁(yè)都不在內(nèi)存,需要讀取10^4個(gè)頁(yè)面,如果這10^4個(gè)頁(yè)面在磁盤(pán)上隨機(jī)分布,需要進(jìn)行10^4次I/O,假設(shè)磁盤(pán)每次I/O時(shí)間為10ms(忽略數(shù)據(jù)傳輸時(shí)間),則總共需要100s(但實(shí)際上要好很多很多)。如果對(duì)之建立B-Tree索引,則只需要進(jìn)行l(wèi)og100(10^6)=3次頁(yè)面讀取,最壞情況下耗時(shí)30ms。這就是索引帶來(lái)的效果,很多時(shí)候,當(dāng)你的應(yīng)用程序進(jìn)行SQL查詢(xún)速度很慢時(shí),應(yīng)該想想是否可以建索引。進(jìn)入正題:
第二章、索引與優(yōu)化
1、選擇索引的數(shù)據(jù)類(lèi)型
MySQL支持很多數(shù)據(jù)類(lèi)型,選擇合適的數(shù)據(jù)類(lèi)型存儲(chǔ)數(shù)據(jù)對(duì)性能有很大的影響。通常來(lái)說(shuō),可以遵循以下一些指導(dǎo)原則:
(1)越小的數(shù)據(jù)類(lèi)型通常更好:越小的數(shù)據(jù)類(lèi)型通常在磁盤(pán)、內(nèi)存和CPU緩存中都需要更少的空間,處理起來(lái)更快。(2)簡(jiǎn)單的數(shù)據(jù)類(lèi)型更好:整型數(shù)據(jù)比起字符,處理開(kāi)銷(xiāo)更小,因?yàn)樽址谋容^更復(fù)雜。在MySQL中,應(yīng)該用內(nèi)置的日期和時(shí)間數(shù)據(jù)類(lèi)型,而不是用字符串來(lái)存儲(chǔ)時(shí)間;以及用整型數(shù)據(jù)類(lèi)型存儲(chǔ)IP地址。(3)盡量避免NULL:應(yīng)該指定列為NOT NULL,除非你想存儲(chǔ)NULL。在MySQL中,含有空值的列很難進(jìn)行查詢(xún)優(yōu)化,因?yàn)樗鼈兪沟盟饕⑺饕慕y(tǒng)計(jì)信息以及比較運(yùn)算更加復(fù)雜。你應(yīng)該用0、一個(gè)特殊的值或者一個(gè)空串代替空值。1.1、選擇標(biāo)識(shí)符選擇合適的標(biāo)識(shí)符是非常重要的。選擇時(shí)不僅應(yīng)該考慮存儲(chǔ)類(lèi)型,而且應(yīng)該考慮MySQL是怎樣進(jìn)行運(yùn)算和比較的。一旦選定數(shù)據(jù)類(lèi)型,應(yīng)該保證所有相關(guān)的表都使用相同的數(shù)據(jù)類(lèi)型。(1) 整型:通常是作為標(biāo)識(shí)符的最好選擇,因?yàn)榭梢愿斓奶幚恚铱梢栽O(shè)置為AUTO_INCREMENT。
(2) 字符串:盡量避免使用字符串作為標(biāo)識(shí)符,它們消耗更好的空間,處理起來(lái)也較慢。而且,通常來(lái)說(shuō),字符串都是隨機(jī)的,所以它們?cè)谒饕械奈恢靡彩请S機(jī)的,這會(huì)導(dǎo)致頁(yè)面分裂、隨機(jī)訪問(wèn)磁盤(pán),聚簇索引分裂(對(duì)于使用聚簇索引的存儲(chǔ)引擎)。
2、索引入門(mén)對(duì)于任何DBMS,索引都是進(jìn)行優(yōu)化的最主要的因素。對(duì)于少量的數(shù)據(jù),沒(méi)有合適的索引影響不是很大,但是,當(dāng)隨著數(shù)據(jù)量的增加,性能會(huì)急劇下降。如果對(duì)多列進(jìn)行索引(組合索引),列的順序非常重要,MySQL僅能對(duì)索引最左邊的前綴進(jìn)行有效的查找。例如:假設(shè)存在組合索引it1c1c2(c1,c2),查詢(xún)語(yǔ)句select * from t1 where c1=1 and c2=2能夠使用該索引。查詢(xún)語(yǔ)句select * from t1 where c1=1也能夠使用該索引。但是,查詢(xún)語(yǔ)句select * from t1 where c2=2不能夠使用該索引,因?yàn)闆](méi)有組合索引的引導(dǎo)列,即,要想使用c2列進(jìn)行查找,必需出現(xiàn)c1等于某值。2.1、索引的類(lèi)型索引是在存儲(chǔ)引擎中實(shí)現(xiàn)的,而不是在服務(wù)器層中實(shí)現(xiàn)的。所以,每種存儲(chǔ)引擎的索引都不一定完全相同,并不是所有的存儲(chǔ)引擎都支持所有的索引類(lèi)型。2.1.1、B-Tree索引假設(shè)有如下一個(gè)表:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dobdate not null,
gender enum(’m’, ’f’) not null,
key(last_name, first_name, dob)
);
其索引包含表中每一行的last_name、first_name和dob列。其結(jié)構(gòu)大致如下:
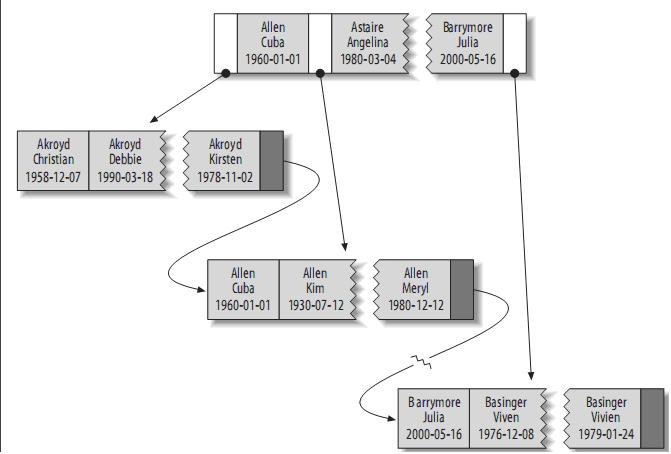
索引存儲(chǔ)的值按索引列中的順序排列。可以利用B-Tree索引進(jìn)行全關(guān)鍵字、關(guān)鍵字范圍和關(guān)鍵字前綴查詢(xún),當(dāng)然,如果想使用索引,你必須保證按索引的最左邊前綴(leftmost prefix of the index)來(lái)進(jìn)行查詢(xún)。(1)匹配全值(Match the full value):對(duì)索引中的所有列都指定具體的值。例如,上圖中索引可以幫助你查找出生于1960-01-01的Cuba Allen。(2)匹配最左前綴(Match a leftmost prefix):你可以利用索引查找last name為Allen的人,僅僅使用索引中的第1列。(3)匹配列前綴(Match a column prefix):例如,你可以利用索引查找last name以J開(kāi)始的人,這僅僅使用索引中的第1列。(4)匹配值的范圍查詢(xún)(Match a range of values):可以利用索引查找last name在Allen和Barrymore之間的人,僅僅使用索引中第1列。(5)匹配部分精確而其它部分進(jìn)行范圍匹配(Match one part exactly and match a range on another part):可以利用索引查找last name為Allen,而first name以字母K開(kāi)始的人。(6)僅對(duì)索引進(jìn)行查詢(xún)(Index-only queries):如果查詢(xún)的列都位于索引中,則不需要讀取元組的值。由于B-樹(shù)中的節(jié)點(diǎn)都是順序存儲(chǔ)的,所以可以利用索引進(jìn)行查找(找某些值),也可以對(duì)查詢(xún)結(jié)果進(jìn)行ORDER BY。當(dāng)然,使用B-tree索引有以下一些限制:(1) 查詢(xún)必須從索引的最左邊的列開(kāi)始。關(guān)于這點(diǎn)已經(jīng)提了很多遍了。例如你不能利用索引查找在某一天出生的人。(2) 不能跳過(guò)某一索引列。例如,你不能利用索引查找last name為Smith且出生于某一天的人。(3) 存儲(chǔ)引擎不能使用索引中范圍條件右邊的列。例如,如果你的查詢(xún)語(yǔ)句為WHERE last_name='Smith' AND first_name LIKE ’J%’ AND dob=’1976-12-23’,則該查詢(xún)只會(huì)使用索引中的前兩列,因?yàn)長(zhǎng)IKE是范圍查詢(xún)。
2.1.2、Hash索引MySQL中,只有Memory存儲(chǔ)引擎顯示支持hash索引,是Memory表的默認(rèn)索引類(lèi)型,盡管Memory表也可以使用B-Tree索引。Memory存儲(chǔ)引擎支持非唯一hash索引,這在數(shù)據(jù)庫(kù)領(lǐng)域是罕見(jiàn)的,如果多個(gè)值有相同的hash code,索引把它們的行指針用鏈表保存到同一個(gè)hash表項(xiàng)中。假設(shè)創(chuàng)建如下一個(gè)表:CREATE TABLE testhash ( fname VARCHAR(50) NOT NULL, lname VARCHAR(50) NOT NULL, KEY USING HASH(fname)) ENGINE=MEMORY;包含的數(shù)據(jù)如下: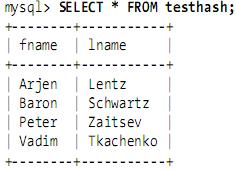
假設(shè)索引使用hash函數(shù)f( ),如下:
f(’Arjen’) = 2323
f(’Baron’) = 7437
f(’Peter’) = 8784
f(’Vadim’) = 2458
此時(shí),索引的結(jié)構(gòu)大概如下:
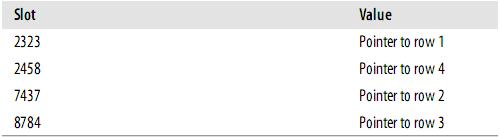
Slots是有序的,但是記錄不是有序的。當(dāng)你執(zhí)行mysql> SELECT lname FROM testhash WHERE fname=’Peter’;MySQL會(huì)計(jì)算’Peter’的hash值,然后通過(guò)它來(lái)查詢(xún)索引的行指針。因?yàn)閒(’Peter’) = 8784,MySQL會(huì)在索引中查找8784,得到指向記錄3的指針。因?yàn)樗饕约簝H僅存儲(chǔ)很短的值,所以,索引非常緊湊。Hash值不取決于列的數(shù)據(jù)類(lèi)型,一個(gè)TINYINT列的索引與一個(gè)長(zhǎng)字符串列的索引一樣大。 Hash索引有以下一些限制:(1)由于索引僅包含hash code和記錄指針,所以,MySQL不能通過(guò)使用索引避免讀取記錄。但是訪問(wèn)內(nèi)存中的記錄是非常迅速的,不會(huì)對(duì)性造成太大的影響。(2)不能使用hash索引排序。(3)Hash索引不支持鍵的部分匹配,因?yàn)槭峭ㄟ^(guò)整個(gè)索引值來(lái)計(jì)算hash值的。(4)Hash索引只支持等值比較,例如使用=,IN( )和<=>。對(duì)于WHERE price>100并不能加速查詢(xún)。2.1.3、空間(R-Tree)索引MyISAM支持空間索引,主要用于地理空間數(shù)據(jù)類(lèi)型,例如GEOMETRY。2.1.4、全文(Full-text)索引全文索引是MyISAM的一個(gè)特殊索引類(lèi)型,主要用于全文檢索。
3、高性能的索引策略3.1、聚簇索引(Clustered Indexes)聚簇索引保證關(guān)鍵字的值相近的元組存儲(chǔ)的物理位置也相同(所以字符串類(lèi)型不宜建立聚簇索引,特別是隨機(jī)字符串,會(huì)使得系統(tǒng)進(jìn)行大量的移動(dòng)操作),且一個(gè)表只能有一個(gè)聚簇索引。因?yàn)橛纱鎯?chǔ)引擎實(shí)現(xiàn)索引,所以,并不是所有的引擎都支持聚簇索引。目前,只有solidDB和InnoDB支持。聚簇索引的結(jié)構(gòu)大致如下: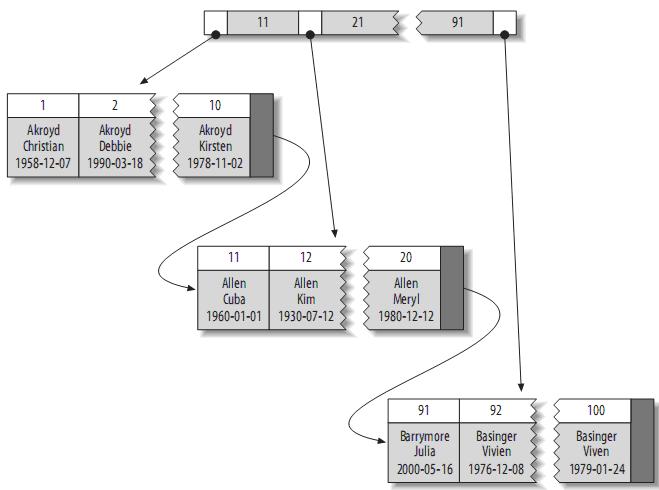
注:葉子頁(yè)面包含完整的元組,而內(nèi)節(jié)點(diǎn)頁(yè)面僅包含索引的列(索引的列為整型)。一些DBMS允許用戶(hù)指定聚簇索引,但是MySQL的存儲(chǔ)引擎到目前為止都不支持。InnoDB對(duì)主鍵建立聚簇索引。如果你不指定主鍵,InnoDB會(huì)用一個(gè)具有唯一且非空值的索引來(lái)代替。如果不存在這樣的索引,InnoDB會(huì)定義一個(gè)隱藏的主鍵,然后對(duì)其建立聚簇索引。一般來(lái)說(shuō),DBMS都會(huì)以聚簇索引的形式來(lái)存儲(chǔ)實(shí)際的數(shù)據(jù),它是其它二級(jí)索引的基礎(chǔ)。
3.1.1、InnoDB和MyISAM的數(shù)據(jù)布局的比較為了更加理解聚簇索引和非聚簇索引,或者primary索引和second索引(MyISAM不支持聚簇索引),來(lái)比較一下InnoDB和MyISAM的數(shù)據(jù)布局,對(duì)于如下表:
CREATE TABLE layout_test (
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);
假設(shè)主鍵的值位于1---10,000之間,且按隨機(jī)順序插入,然后用OPTIMIZE TABLE進(jìn)行優(yōu)化。col2隨機(jī)賦予1---100之間的值,所以會(huì)存在許多重復(fù)的值。(1) MyISAM的數(shù)據(jù)布局其布局十分簡(jiǎn)單,MyISAM按照插入的順序在磁盤(pán)上存儲(chǔ)數(shù)據(jù),如下: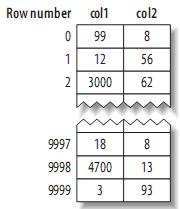
注:左邊為行號(hào)(row number),從0開(kāi)始。因?yàn)樵M的大小固定,所以MyISAM可以很容易的從表的開(kāi)始位置找到某一字節(jié)的位置。據(jù)些建立的primary key的索引結(jié)構(gòu)大致如下: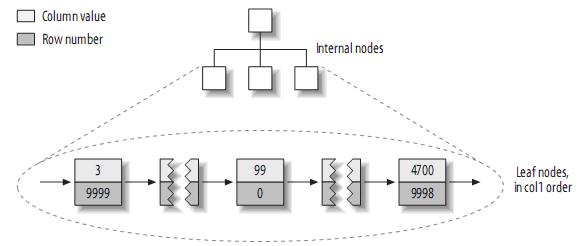
注:MyISAM不支持聚簇索引,索引中每一個(gè)葉子節(jié)點(diǎn)僅僅包含行號(hào)(row number),且葉子節(jié)點(diǎn)按照col1的順序存儲(chǔ)。來(lái)看看col2的索引結(jié)構(gòu):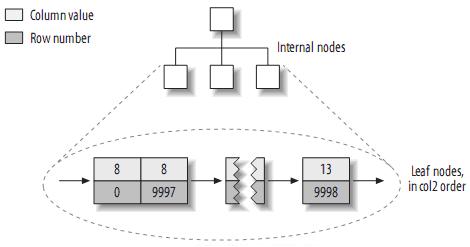
實(shí)際上,在MyISAM中,primary key和其它索引沒(méi)有什么區(qū)別。Primary key僅僅只是一個(gè)叫做PRIMARY的唯一,非空的索引而已。(2) InnoDB的數(shù)據(jù)布局InnoDB按聚簇索引的形式存儲(chǔ)數(shù)據(jù),所以它的數(shù)據(jù)布局有著很大的不同。它存儲(chǔ)表的結(jié)構(gòu)大致如下: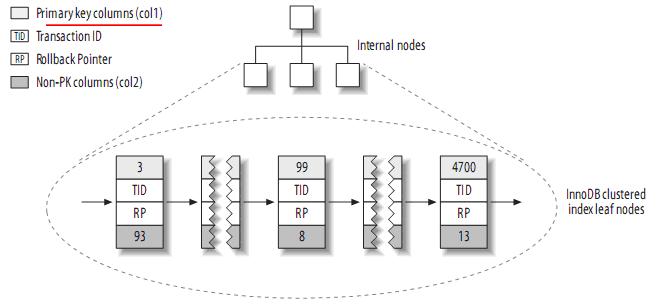
注:聚簇索引中的每個(gè)葉子節(jié)點(diǎn)包含primary key的值,事務(wù)ID和回滾指針(rollback pointer)——用于事務(wù)和MVCC,和余下的列(如col2)。相對(duì)于MyISAM,二級(jí)索引與聚簇索引有很大的不同。InnoDB的二級(jí)索引的葉子包含primary key的值,而不是行指針(row pointers),這減小了移動(dòng)數(shù)據(jù)或者數(shù)據(jù)頁(yè)面分裂時(shí)維護(hù)二級(jí)索引的開(kāi)銷(xiāo),因?yàn)镮nnoDB不需要更新索引的行指針。其結(jié)構(gòu)大致如下: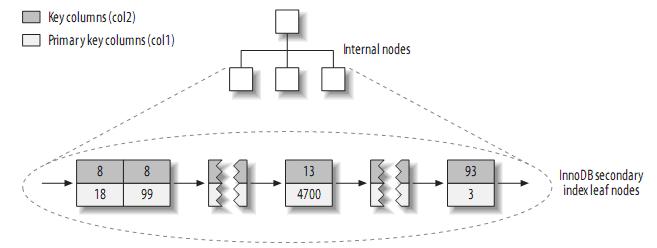
聚簇索引和非聚簇索引表的對(duì)比:
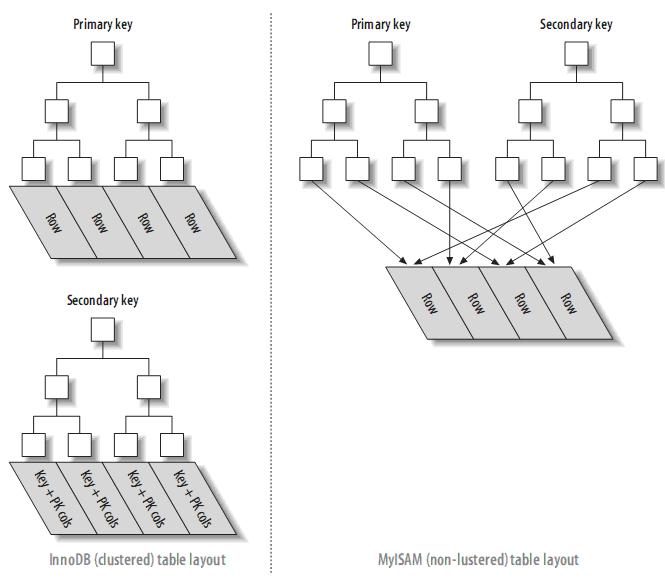
3.1.2、按primary key的順序插入行(InnoDB)
如果你用InnoDB,而且不需要特殊的聚簇索引,一個(gè)好的做法就是使用代理主鍵(surrogate key)——獨(dú)立于你的應(yīng)用中的數(shù)據(jù)。最簡(jiǎn)單的做法就是使用一個(gè)AUTO_INCREMENT的列,這會(huì)保證記錄按照順序插入,而且能提高使用primary key進(jìn)行連接的查詢(xún)的性能。應(yīng)該盡量避免隨機(jī)的聚簇主鍵,例如,字符串主鍵就是一個(gè)不好的選擇,它使得插入操作變得隨機(jī)。
3.2、覆蓋索引(Covering Indexes)如果索引包含滿(mǎn)足查詢(xún)的所有數(shù)據(jù),就稱(chēng)為覆蓋索引。覆蓋索引是一種非常強(qiáng)大的工具,能大大提高查詢(xún)性能。只需要讀取索引而不用讀取數(shù)據(jù)有以下一些優(yōu)點(diǎn):(1)索引項(xiàng)通常比記錄要小,所以MySQL訪問(wèn)更少的數(shù)據(jù);(2)索引都按值的大小順序存儲(chǔ),相對(duì)于隨機(jī)訪問(wèn)記錄,需要更少的I/O;(3)大多數(shù)據(jù)引擎能更好的緩存索引。比如MyISAM只緩存索引。(4)覆蓋索引對(duì)于InnoDB表尤其有用,因?yàn)镮nnoDB使用聚集索引組織數(shù)據(jù),如果二級(jí)索引中包含查詢(xún)所需的數(shù)據(jù),就不再需要在聚集索引中查找了。覆蓋索引不能是任何索引,只有B-TREE索引存儲(chǔ)相應(yīng)的值。而且不同的存儲(chǔ)引擎實(shí)現(xiàn)覆蓋索引的方式都不同,并不是所有存儲(chǔ)引擎都支持覆蓋索引(Memory和Falcon就不支持)。對(duì)于索引覆蓋查詢(xún)(index-covered query),使用EXPLAIN時(shí),可以在Extra一列中看到“Using index”。例如,在sakila的inventory表中,有一個(gè)組合索引(store_id,film_id),對(duì)于只需要訪問(wèn)這兩列的查詢(xún),MySQL就可以使用索引,如下:
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventoryG
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: inventory
type: index
possible_keys: NULL
key: idx_store_id_film_id
key_len: 3
ref: NULL
rows: 5007
Extra: Using index
1 row in set (0.17 sec)
在大多數(shù)引擎中,只有當(dāng)查詢(xún)語(yǔ)句所訪問(wèn)的列是索引的一部分時(shí),索引才會(huì)覆蓋。但是,InnoDB不限于此,InnoDB的二級(jí)索引在葉子節(jié)點(diǎn)中存儲(chǔ)了primary key的值。因此,sakila.actor表使用InnoDB,而且對(duì)于是last_name上有索引,所以,索引能覆蓋那些訪問(wèn)actor_id的查詢(xún),如:
mysql> EXPLAIN SELECT actor_id, last_name
-> FROM sakila.actor WHERE last_name = ’HOPPER’G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
type: ref
possible_keys: idx_actor_last_name
key: idx_actor_last_name
key_len: 137
ref: const
rows: 2
Extra: Using where; Using index
3.3、利用索引進(jìn)行排序MySQL中,有兩種方式生成有序結(jié)果集:一是使用filesort,二是按索引順序掃描。利用索引進(jìn)行排序操作是非常快的,而且可以利用同一索引同時(shí)進(jìn)行查找和排序操作。當(dāng)索引的順序與ORDER BY中的列順序相同且所有的列是同一方向(全部升序或者全部降序)時(shí),可以使用索引來(lái)排序。如果查詢(xún)是連接多個(gè)表,僅當(dāng)ORDER BY中的所有列都是第一個(gè)表的列時(shí)才會(huì)使用索引。其它情況都會(huì)使用filesort。
create table actor(
actor_id int unsigned NOT NULL AUTO_INCREMENT,
name varchar(16) NOT NULL DEFAULT ’’,
passwordvarchar(16) NOT NULL DEFAULT ’’,
PRIMARY KEY(actor_id),
KEY (name)
) ENGINE=InnoDB
insert into actor(name,password) values(’cat01’,’1234567’);
insert into actor(name,password) values(’cat02’,’1234567’);
insert into actor(name,password) values(’ddddd’,’1234567’);
insert into actor(name,password) values(’aaaaa’,’1234567’);
mysql> explain select actor_id from actor order by actor_id G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
type: index
possible_keys: NULL
key: PRIMARY
key_len: 4
ref: NULL
rows: 4
Extra: Using index
1 row in set (0.00 sec)
mysql> explain select actor_id from actor order by password G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Using filesort
1 row in set (0.00 sec)
mysql> explain select actor_id from actor order by name G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
type: index
possible_keys: NULL
key: name
key_len: 18
ref: NULL
rows: 4
Extra: Using index
1 row in set (0.00 sec)
當(dāng)MySQL不能使用索引進(jìn)行排序時(shí),就會(huì)利用自己的排序算法(快速排序算法)在內(nèi)存(sort buffer)中對(duì)數(shù)據(jù)進(jìn)行排序,如果內(nèi)存裝載不下,它會(huì)將磁盤(pán)上的數(shù)據(jù)進(jìn)行分塊,再對(duì)各個(gè)數(shù)據(jù)塊進(jìn)行排序,然后將各個(gè)塊合并成有序的結(jié)果集(實(shí)際上就是外排序)。對(duì)于filesort,MySQL有兩種排序算法。(1)兩遍掃描算法(Two passes)實(shí)現(xiàn)方式是先將須要排序的字段和可以直接定位到相關(guān)行數(shù)據(jù)的指針信息取出,然后在設(shè)定的內(nèi)存(通過(guò)參數(shù)sort_buffer_size設(shè)定)中進(jìn)行排序,完成排序之后再次通過(guò)行指針信息取出所需的Columns。注:該算法是4.1之前采用的算法,它需要兩次訪問(wèn)數(shù)據(jù),尤其是第二次讀取操作會(huì)導(dǎo)致大量的隨機(jī)I/O操作。另一方面,內(nèi)存開(kāi)銷(xiāo)較小。(3) 一次掃描算法(single pass)該算法一次性將所需的Columns全部取出,在內(nèi)存中排序后直接將結(jié)果輸出。注:從 MySQL 4.1 版本開(kāi)始使用該算法。它減少了I/O的次數(shù),效率較高,但是內(nèi)存開(kāi)銷(xiāo)也較大。如果我們將并不需要的Columns也取出來(lái),就會(huì)極大地浪費(fèi)排序過(guò)程所需要的內(nèi)存。在 MySQL 4.1 之后的版本中,可以通過(guò)設(shè)置 max_length_for_sort_data 參數(shù)來(lái)控制 MySQL 選擇第一種排序算法還是第二種。當(dāng)取出的所有大字段總大小大于 max_length_for_sort_data 的設(shè)置時(shí),MySQL 就會(huì)選擇使用第一種排序算法,反之,則會(huì)選擇第二種。為了盡可能地提高排序性能,我們自然更希望使用第二種排序算法,所以在 Query 中僅僅取出需要的 Columns 是非常有必要的。當(dāng)對(duì)連接操作進(jìn)行排序時(shí),如果ORDER BY僅僅引用第一個(gè)表的列,MySQL對(duì)該表進(jìn)行filesort操作,然后進(jìn)行連接處理,此時(shí),EXPLAIN輸出“Using filesort”;否則,MySQL必須將查詢(xún)的結(jié)果集生成一個(gè)臨時(shí)表,在連接完成之后進(jìn)行filesort操作,此時(shí),EXPLAIN輸出“Using temporary;Using filesort”。
3.4、索引與加鎖索引對(duì)于InnoDB非常重要,因?yàn)樗梢宰尣樵?xún)鎖更少的元組。這點(diǎn)十分重要,因?yàn)镸ySQL 5.0中,InnoDB直到事務(wù)提交時(shí)才會(huì)解鎖。有兩個(gè)方面的原因:首先,即使InnoDB行級(jí)鎖的開(kāi)銷(xiāo)非常高效,內(nèi)存開(kāi)銷(xiāo)也較小,但不管怎么樣,還是存在開(kāi)銷(xiāo)。其次,對(duì)不需要的元組的加鎖,會(huì)增加鎖的開(kāi)銷(xiāo),降低并發(fā)性。InnoDB僅對(duì)需要訪問(wèn)的元組加鎖,而索引能夠減少I(mǎi)nnoDB訪問(wèn)的元組數(shù)。但是,只有在存儲(chǔ)引擎層過(guò)濾掉那些不需要的數(shù)據(jù)才能達(dá)到這種目的。一旦索引不允許InnoDB那樣做(即達(dá)不到過(guò)濾的目的),MySQL服務(wù)器只能對(duì)InnoDB返回的數(shù)據(jù)進(jìn)行WHERE操作,此時(shí),已經(jīng)無(wú)法避免對(duì)那些元組加鎖了:InnoDB已經(jīng)鎖住那些元組,服務(wù)器無(wú)法解鎖了。來(lái)看個(gè)例子:
create table actor(
actor_id int unsigned NOT NULL AUTO_INCREMENT,
name varchar(16) NOT NULL DEFAULT ’’,
passwordvarchar(16) NOT NULL DEFAULT ’’,
PRIMARY KEY(actor_id),
KEY (name)
) ENGINE=InnoDB
insert into actor(name,password) values(’cat01’,’1234567’);
insert into actor(name,password) values(’cat02’,’1234567’);
insert into actor(name,password) values(’ddddd’,’1234567’);
insert into actor(name,password) values(’aaaaa’,’1234567’);
SET AUTOCOMMIT=0;
BEGIN;
SELECT actor_id FROM actor WHERE actor_id < 4
AND actor_id <> 1 FOR UPDATE;
該查詢(xún)僅僅返回2---3的數(shù)據(jù),實(shí)際已經(jīng)對(duì)1---3的數(shù)據(jù)加上排它鎖了。InnoDB鎖住元組1是因?yàn)镸ySQL的查詢(xún)計(jì)劃僅使用索引進(jìn)行范圍查詢(xún)(而沒(méi)有進(jìn)行過(guò)濾操作,WHERE中第二個(gè)條件已經(jīng)無(wú)法使用索引了):
mysql> EXPLAIN SELECT actor_id FROM test.actor
-> WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
type: index
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 4
Extra: Using where; Using index
1 row in set (0.00 sec)
mysql>
表明存儲(chǔ)引擎從索引的起始處開(kāi)始,獲取所有的行,直到actor_id<4為假,服務(wù)器無(wú)法告訴InnoDB去掉元組1。為了證明row 1已經(jīng)被鎖住,我們另外建一個(gè)連接,執(zhí)行如下操作:
SET AUTOCOMMIT=0;
BEGIN;
SELECT actor_id FROM actor WHERE actor_id = 1 FOR UPDATE;
該查詢(xún)會(huì)被掛起,直到第一個(gè)連接的事務(wù)提交釋放鎖時(shí),才會(huì)執(zhí)行(這種行為對(duì)于基于語(yǔ)句的復(fù)制(statement-based replication)是必要的)。如上所示,當(dāng)使用索引時(shí),InnoDB會(huì)鎖住它不需要的元組。更糟糕的是,如果查詢(xún)不能使用索引,MySQL會(huì)進(jìn)行全表掃描,并鎖住每一個(gè)元組,不管是否真正需要。
來(lái)自: http://blog.csdn.net/kingmax54212008/article/details/51699148
相關(guān)文章:
1. 在SQL Server 2005修改存儲(chǔ)過(guò)程2. mybatis中方法返回泛型與resultType不一致的解決3. SQL Server全文檢索簡(jiǎn)介4. 服務(wù)器Centos部署MySql并連接Navicat過(guò)程詳解5. Oracle中pivot函數(shù)圖文實(shí)例詳解6. Docker部署Mysql集群的實(shí)現(xiàn)7. Oracle?Users表空間重命名問(wèn)題解決8. MySQL 的啟動(dòng)和連接方式實(shí)例分析9. SQL SERVER數(shù)據(jù)庫(kù)開(kāi)發(fā)之存儲(chǔ)過(guò)程的應(yīng)用10. idea連接SQL Server數(shù)據(jù)庫(kù)的詳細(xì)圖文教程

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備