JavaScript中對(duì)于SPA單頁(yè)面的理解
目錄
- 一、什么是SPA
- 二、SPA和MPA的區(qū)別
- 單頁(yè)應(yīng)用與多頁(yè)應(yīng)用的區(qū)別
- 單頁(yè)應(yīng)用優(yōu)缺點(diǎn)
- 三、實(shí)現(xiàn)一個(gè)SPA
- 四、如何給SPA做SEO
一、什么是SPA
SPA(single-page application),翻譯過(guò)來(lái)就是單頁(yè)應(yīng)用SPA是一種網(wǎng)絡(luò)應(yīng)用程序或網(wǎng)站的模型,它通過(guò)動(dòng)態(tài)重寫(xiě)當(dāng)前頁(yè)面來(lái)與用戶交互,這種方法避免了頁(yè)面之間切換打斷用戶體驗(yàn)在單頁(yè)應(yīng)用中,所有必要的代碼(HTML、JavaScript和CSS)都通過(guò)單個(gè)頁(yè)面的加載而檢索,或者根據(jù)需要(通常是為響應(yīng)用戶操作)動(dòng)態(tài)裝載適當(dāng)?shù)馁Y源并添加到頁(yè)面頁(yè)面在任何時(shí)間點(diǎn)都不會(huì)重新加載,也不會(huì)將控制轉(zhuǎn)移到其他頁(yè)面舉個(gè)例子來(lái)講就是一個(gè)杯子,早上裝的牛奶,中午裝的是開(kāi)水,晚上裝的是茶,我們發(fā)現(xiàn),變的始終是杯子里的內(nèi)容,而杯子始終是那個(gè)杯子結(jié)構(gòu)如下圖
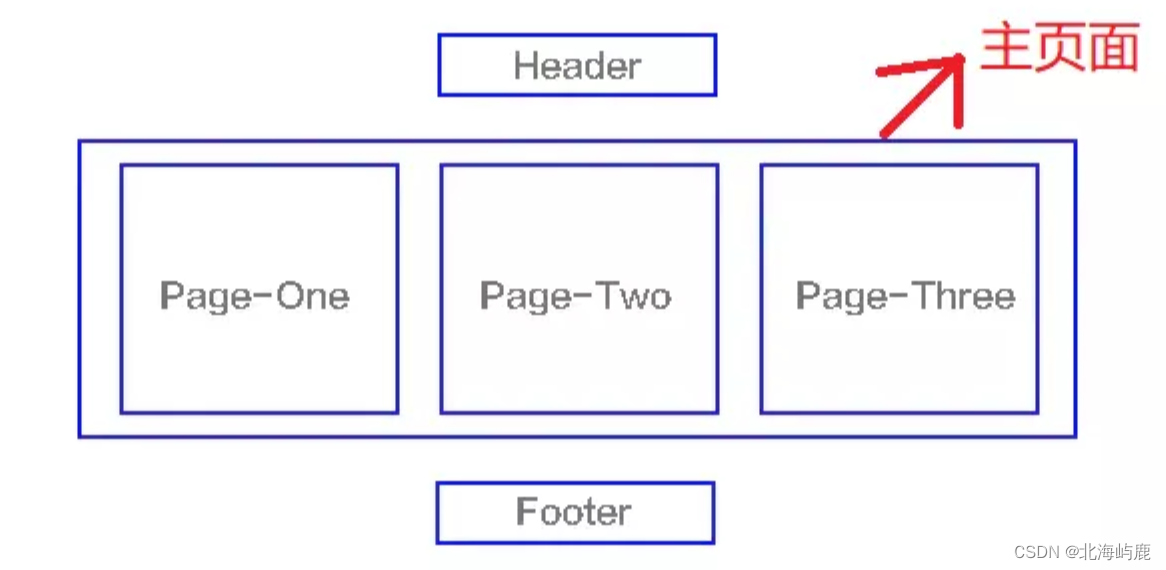
我們熟知的JS框架如react,vue,angular,ember都屬于SPA
二、SPA和MPA的區(qū)別
上面大家已經(jīng)對(duì)單頁(yè)面有所了解了,下面來(lái)講講多頁(yè)應(yīng)用MPA(MultiPage-page application),翻譯過(guò)來(lái)就是多頁(yè)應(yīng)用在MPA中,每個(gè)頁(yè)面都是一個(gè)主頁(yè)面,都是獨(dú)立的當(dāng)我們?cè)谠L問(wèn)另一個(gè)頁(yè)面的時(shí)候,都需要重新加載html、css、js文件,公共文件則根據(jù)需求按需加載如下圖
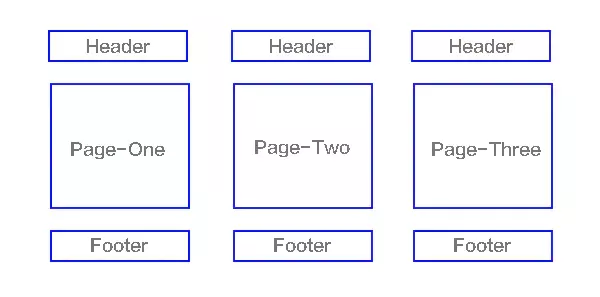
單頁(yè)應(yīng)用與多頁(yè)應(yīng)用的區(qū)別
單頁(yè)應(yīng)用優(yōu)缺點(diǎn)
優(yōu)點(diǎn):
- 具有桌面應(yīng)用的即時(shí)性、網(wǎng)站的可移植性和可訪問(wèn)性
- 用戶體驗(yàn)好、快,內(nèi)容的改變不需要重新加載整個(gè)頁(yè)面
- 良好的前后端分離,分工更明確
缺點(diǎn):
- 不利于搜索引擎的抓取
- 首次渲染速度相對(duì)較慢
三、實(shí)現(xiàn)一個(gè)SPA
- 監(jiān)聽(tīng)地址欄中
hash變化驅(qū)動(dòng)界面變化 - 用
pushsate記錄瀏覽器的歷史,驅(qū)動(dòng)界面發(fā)送變化
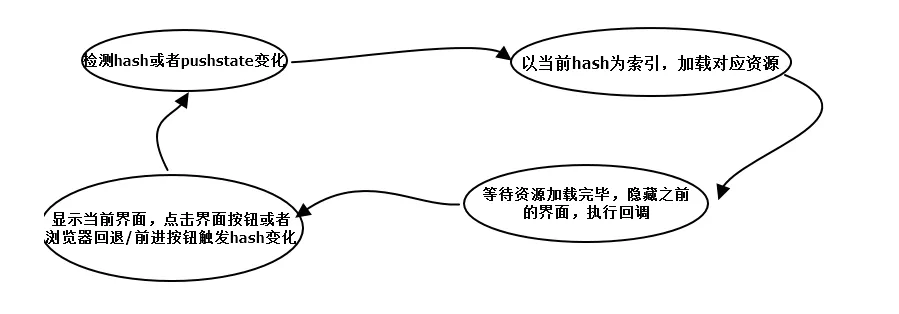
實(shí)現(xiàn)
hash模式
核心通過(guò)監(jiān)聽(tīng)url中的hash來(lái)進(jìn)行路由跳轉(zhuǎn)
// 定義 Router class Router { constructor () { this.routes = {}; // 存放路由path及callback this.currentUrl = ""; // 監(jiān)聽(tīng)路由change調(diào)用相對(duì)應(yīng)的路由回調(diào) window.addEventListener("load", this.refresh, false); window.addEventListener("hashchange", this.refresh, false); } route(path, callback){ this.routes[path] = callback; } push(path) { this.routes[path] && this.routes[path]() } } // 使用 router window.miniRouter = new Router(); miniRouter.route("/", () => console.log("page1")) miniRouter.route("/page2", () => console.log("page2")) miniRouter.push("/") // page1 miniRouter.push("/page2") // page2 history模式
history模式核心借用HTML5 history api,api提供了豐富的router相關(guān)屬性先了解一個(gè)幾個(gè)相關(guān)的api
history.pushState瀏覽器歷史紀(jì)錄添加記錄history.replaceState修改瀏覽器歷史紀(jì)錄中當(dāng)前紀(jì)錄history.popState當(dāng)history發(fā)生變化時(shí)觸發(fā)
// 定義 Router class Router { constructor () { this.routes = {}; this.listerPopState() } init(path) { history.replaceState({path: path}, null, path); this.routes[path] && this.routes[path](); } route(path, callback){ this.routes[path] = callback; } push(path) { history.pushState({path: path}, null, path); this.routes[path] && this.routes[path](); } listerPopState () { window.addEventListener("popstate" , e => { const path = e.state && e.state.path; this.routers[path] && this.routers[path]() }) } } // 使用 Router window.miniRouter = new Router(); miniRouter.route("/", ()=> console.log("page1")) miniRouter.route("/page2", ()=> console.log("page2")) // 跳轉(zhuǎn) miniRouter.push("/page2") // page2 四、如何給SPA做SEO
下面給出基于Vue的SPA如何實(shí)現(xiàn)SEO的三種方式
SSR服務(wù)端渲染
將組件或頁(yè)面通過(guò)服務(wù)器生成html,再返回給瀏覽器,如nuxt.js
靜態(tài)化
目前主流的靜態(tài)化主要有兩種:
(1)一種是通過(guò)程序?qū)?dòng)態(tài)頁(yè)面抓取并保存為靜態(tài)頁(yè)面,這樣的頁(yè)面的實(shí)際存在于服務(wù)器的硬盤(pán)中
(2)另外一種是通過(guò)WEB服務(wù)器的URL Rewrite的方式,它的原理是通過(guò)web服務(wù)器內(nèi)部模塊按一定規(guī)則將外部的URL請(qǐng)求轉(zhuǎn)化為內(nèi)部的文件地址,一句話來(lái)說(shuō)就是把外部請(qǐng)求的靜態(tài)地址轉(zhuǎn)化為實(shí)際的動(dòng)態(tài)頁(yè)面地址,而靜態(tài)頁(yè)面實(shí)際是不存在的。
這兩種方法都達(dá)到了實(shí)現(xiàn)URL靜態(tài)化的效果
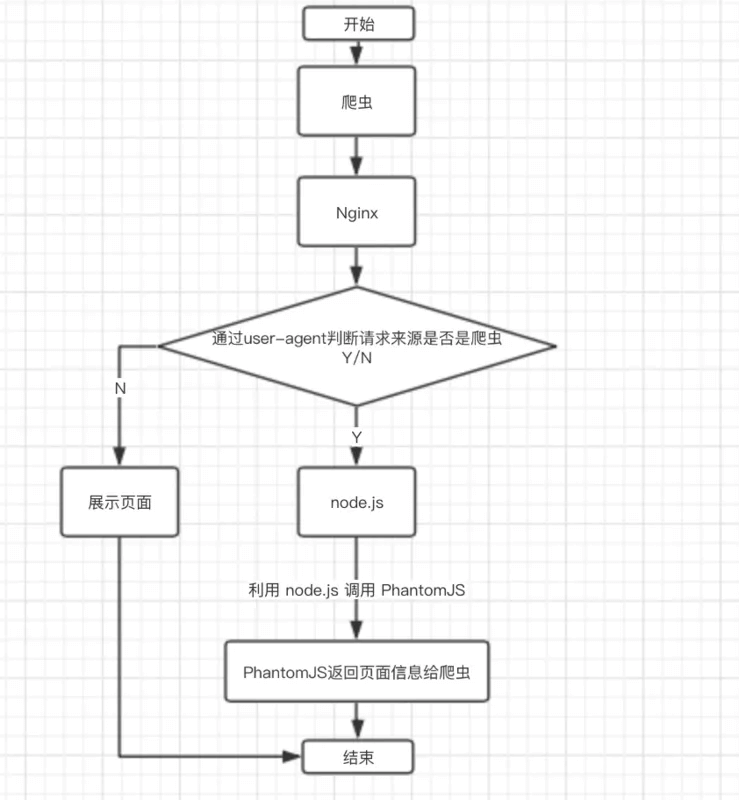
使用Phantomjs針對(duì)爬蟲(chóng)處理
原理是通過(guò)Nginx配置,判斷訪問(wèn)來(lái)源是否為爬蟲(chóng),如果是則搜索引擎的爬蟲(chóng)請(qǐng)求會(huì)轉(zhuǎn)發(fā)到一個(gè)node server,再通過(guò)PhantomJS來(lái)解析完整的HTML,返回給爬蟲(chóng)。下面是大致流程圖
到此這篇關(guān)于JavaScript中對(duì)于SPA單頁(yè)面的理解的文章就介紹到這了,更多相關(guān)JS SPA單頁(yè)面內(nèi)容請(qǐng)搜索以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持!
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備