基于Apache Hudi在Google云構建數據湖平臺的思路詳解
自從計算機出現以來,我們一直在嘗試尋找計算機存儲一些信息的方法,存儲在計算機上的信息(也稱為數據)有多種形式,數據變得如此重要,以至于信息現在已成為觸手可及的商品。多年來數據以多種方式存儲在計算機中,包括數據庫、blob存儲和其他方法,為了進行有效的業務分析,必須對現代應用程序創建的數據進行處理和分析,并且產生的數據量非常巨大!有效地存儲數PB數據并擁有必要的工具來查詢它以便使用它至關重要,只有這樣對該數據的分析才能產生有意義的結果。
大數據是一門處理分析方法、有條不紊地從中提取信息或以其他方式處理對于典型數據處理應用程序軟件而言過于龐大或復雜的數據量的方法的學科。為了處理現代應用程序產生的數據,大數據的應用是非常必要的,考慮到這一點,本博客旨在提供一個關于如何創建數據湖的小教程,該數據湖從應用程序的數據庫中讀取任何更改并將其寫入數據湖中的相關位置,我們將為此使用的工具如下:
- Debezium
- MySQL
- Apache Kafka
- Apache Hudi
- Apache Spark
我們將要構建的數據湖架構如下:
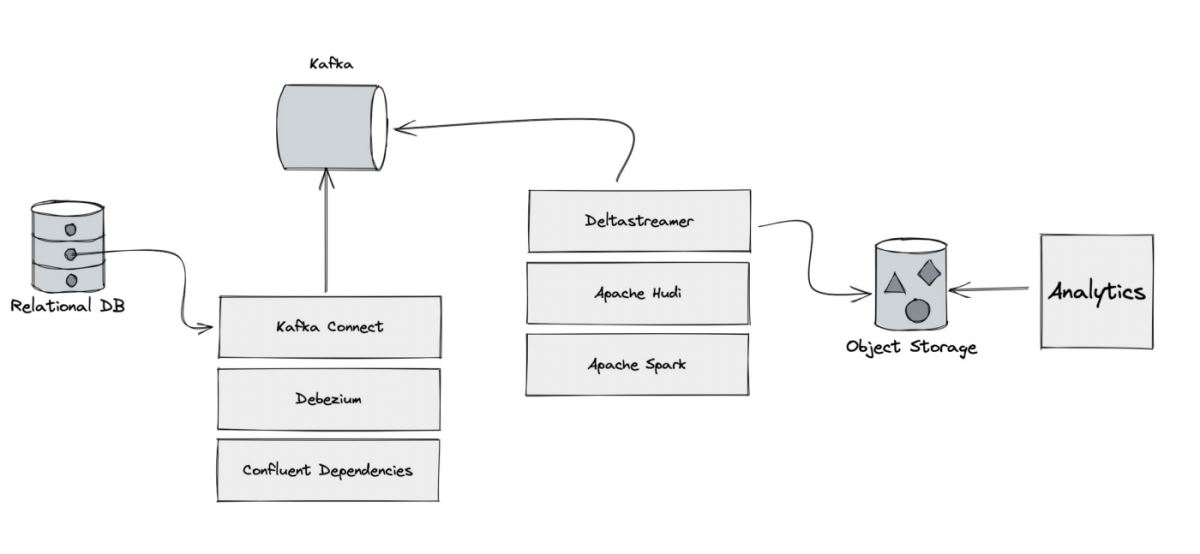
第一步是使用 Debezium 讀取關系數據庫中發生的所有更改,并將所有更改推送到 Kafka 集群。
Debezium 是一個用于變更數據捕獲的開源分布式平臺,Debezium 可以指向任何關系數據庫,并且它可以開始實時捕獲任何數據更改,它非常快速且實用,由紅帽維護。
首先,我們將使用 docker-compose 在我們的機器上設置 Debezium、MySQL 和 Kafka,您也可以使用這些的獨立安裝,我們將使用 Debezium 提供給我們的 mysql 鏡像,因為其中已經包含數據,在任何生產環境中都可以使用適當的 Kafka、MySQL 和 Debezium 集群,docker compose 文件如下:
version: "2"services: zookeeper: image: debezium/zookeeper:${DEBEZIUM_VERSION} ports: - 2181:2181 - 2888:2888 - 3888:3888 kafka: image: debezium/kafka:${DEBEZIUM_VERSION} ports: - 9092:9092 links: - zookeeper environment: - ZOOKEEPER_CONNECT=zookeeper:2181 mysql: image: debezium/example-mysql:${DEBEZIUM_VERSION} ports: - 3307:3306 environment: - MYSQL_ROOT_PASSWORD=${MYSQL_ROOT_PASS} - MYSQL_USER=${MYSQL_USER} - MYSQL_PASSWORD=${MYSQL_USER_PASS} schema-registry: image: confluentinc/cp-schema-registry ports: - 8181:8181 - 8081:8081 environment: - SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS=kafka:9092 - SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL=zookeeper:2181 - SCHEMA_REGISTRY_HOST_NAME=schema-registry - SCHEMA_REGISTRY_LISTENERS=http://schema-registry:8081 links: - zookeeper connect: image: debezium/connect:${DEBEZIUM_VERSION} ports: - 8083:8083 links: - kafka - mysql - schema-registry environment: - BOOTSTRAP_SERVERS=kafka:9092 - GROUP_ID=1 - CONFIG_STORAGE_TOPIC=my_connect_configs - OFFSET_STORAGE_TOPIC=my_connect_offsets - STATUS_STORAGE_TOPIC=my_connect_statuses - KEY_CONVERTER=io.confluent.connect.avro.AvroConverter - VALUE_CONVERTER=io.confluent.connect.avro.AvroConverter - INTERNAL_KEY_CONVERTER=org.apache.kafka.connect.json.JsonConverter - INTERNAL_VALUE_CONVERTER=org.apache.kafka.connect.json.JsonConverter - CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL=http://schema-registry:8081 - CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL=http://schema-registry:8081DEBEZIUM_VERSION 可以設置為 1.8。 此外請確保設置 MYSQL_ROOT_PASS、MYSQL_USER 和 MYSQL_PASSWORD。
在我們繼續之前,我們將查看 debezium 鏡像提供給我們的數據庫 inventory 的結構,進入數據庫的命令行:
docker-compose -f docker-compose-avro-mysql.yaml exec mysql bash -c "mysql -u $MYSQL_USER -p$MYSQL_PASSWORD inventory"
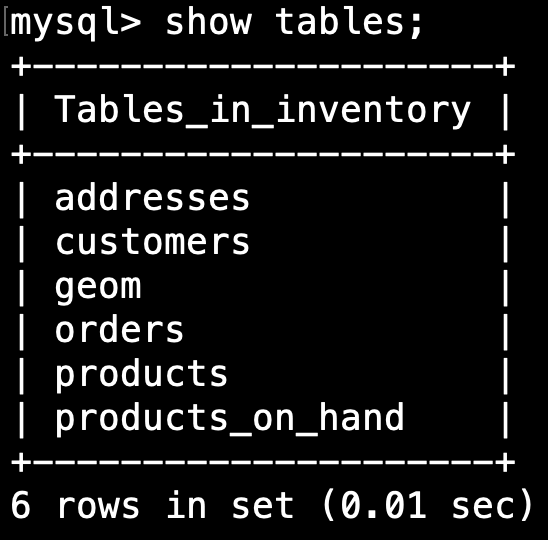
在 shell 內部,我們可以使用 show tables 命令。 輸出應該是這樣的:
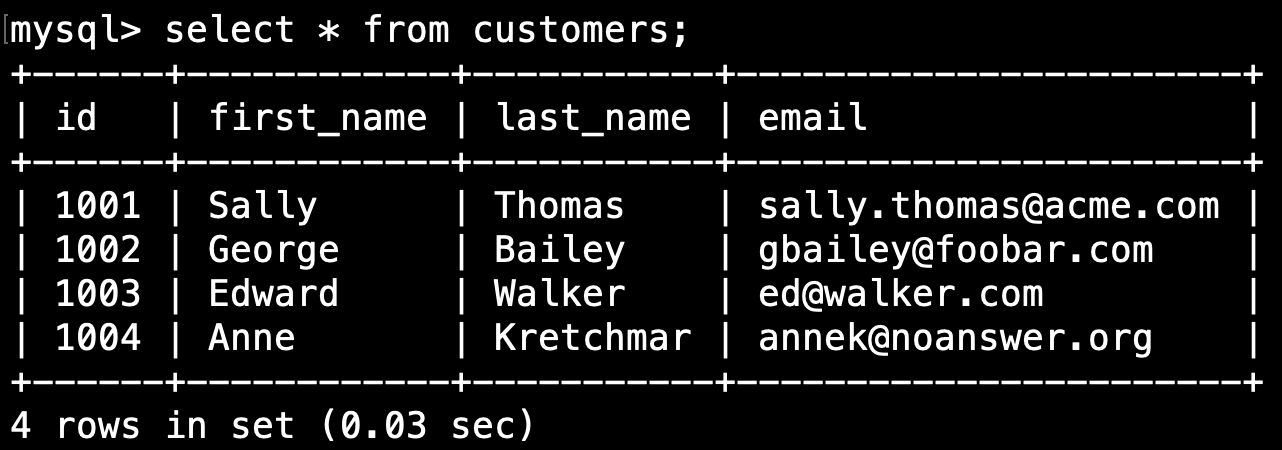
我們可以通過 select * from customers 命令來查看客戶表的內容。 輸出應該是這樣的:
現在在創建容器后,我們將能夠為 Kafka Connect 激活 Debezium 源連接器,我們將使用的數據格式是 Avro 數據格式,Avro 是在 Apache 的 Hadoop 項目中開發的面向行的遠程過程調用和數據序列化框架。它使用 JSON 來定義數據類型和協議,并以緊湊的二進制格式序列化數據。
讓我們用我們的 Debezium 連接器的配置創建另一個文件。
{ "name": "inventory-connector", "config": {"connector.class": "io.debezium.connector.mysql.MySqlConnector","tasks.max": "1","database.hostname": "mysql","database.port": "3306","database.user": "MYSQL_USER","database.password": "MYSQL_PASSWORD","database.server.id": "184054","database.server.name": "dbserver1","database.include.list": "inventory","database.history.kafka.bootstrap.servers": "kafka:9092","database.history.kafka.topic": "schema-changes.inventory","key.converter": "io.confluent.connect.avro.AvroConverter","value.converter": "io.confluent.connect.avro.AvroConverter","key.converter.schema.registry.url": "http://schema-registry:8081","value.converter.schema.registry.url": "http://schema-registry:8081" }}正如我們所看到的,我們已經在其中配置了數據庫的詳細信息以及要從中讀取更改的數據庫,確保將 MYSQL_USER 和 MYSQL_PASSWORD 的值更改為您之前配置的值,現在我們將運行一個命令在 Kafka Connect 中注冊它,命令如下:
curl -i -X POST -H "Accept:application/json" -H "Content-type:application/json" http://localhost:8083/connectors/ -d @register-mysql.json
現在,Debezium 應該能夠從 Kafka 讀取數據庫更改。
下一步涉及使用 Spark 和 Hudi 從 Kafka 讀取數據,并將它們以 Hudi 文件格式放入 Google Cloud Storage Bucket。 在我們開始使用它們之前,讓我們了解一下 Hudi 和 Spark 是什么。
Apache Hudi 是一個開源數據管理框架,用于簡化增量數據處理和數據管道開發。 該框架更有效地管理數據生命周期等業務需求并提高數據質量。 Hudi 使您能夠在基于云的數據湖上管理記錄級別的數據,以簡化更改數據捕獲 (CDC) 和流式數據攝取,并幫助處理需要記錄級別更新和刪除的數據隱私用例。 Hudi 管理的數據集使用開放存儲格式存儲在云存儲桶中,而與 Presto、Apache Hive 和/或 Apache Spark 的集成使用熟悉的工具提供近乎實時的更新數據訪問
Apache Spark 是用于大規模數據處理的開源統一分析引擎。 Spark 為具有隱式數據并行性和容錯性的集群編程提供了一個接口。 Spark 代碼庫最初是在加州大學伯克利分校的 AMPLab 開發的,后來被捐贈給了 Apache 軟件基金會,該基金會一直在維護它。
現在,由于我們正在 Google Cloud 上構建解決方案,因此最好的方法是使用 Google Cloud Dataproc。 Google Cloud Dataproc 是一種托管服務,用于處理大型數據集,例如大數據計劃中使用的數據集。 Dataproc 是 Google 的公共云產品 Google Cloud Platform 的一部分。 Dataproc 幫助用戶處理、轉換和理解大量數據。
在 Google Dataproc 實例中,預裝了 Spark 和所有必需的庫。 創建實例后,我們可以在其中運行以下 Spark 作業來完成我們的管道:
spark-submit \ --packages org.apache.hudi:hudi-spark3.1.2-bundle_2.12:0.10.1,org.apache.spark:spark-avro_2.12:3.1.2 \ --master yarn --deploy-mode client \ --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /usr/lib/hadoop/hudi-packages/hudi-utilities-bundle_2.12-0.10.1.jar \ --table-type COPY_ON_WRITE --op UPSERT \ --target-base-path gs://your-data-lake-bucket/hudi/customers \ --target-table hudi_customers --continuous \ --min-sync-interval-seconds 60 \ --source-class org.apache.hudi.utilities.sources.debezium.MysqlDebeziumSource \ --source-ordering-field _event_origin_ts_ms \ --hoodie-conf schema.registry.url=http://localhost:8081 \ --hoodie-conf hoodie.deltastreamer.schemaprovider.registry.url=http://localhost:8081/subjects/dbserver1.inventory.customers-value/versions/latest \ --hoodie-conf hoodie.deltastreamer.source.kafka.topic=dbserver1.inventory.customers \ --hoodie-conf bootstrap.servers=localhost:9092 \ --hoodie-conf auto.offset.reset=earliest \ --hoodie-conf hoodie.datasource.write.recordkey.field=id \ --hoodie-conf hoodie.datasource.write.partitionpath.field=id \
這將運行一個 spark 作業,該作業從我們之前推送到的 Kafka 中獲取數據并將其寫入 Google Cloud Storage Bucket。 我們必須指定 Kafka 主題、Schema Registry URL 和其他相關配置。
結論
可以通過多種方式構建數據湖。 我試圖展示如何使用 Debezium、Kafka、Hudi、Spark 和 Google Cloud 構建數據湖。 使用這樣的設置,可以輕松擴展管道以管理大量數據工作負載! 有關每種技術的更多詳細信息,可以訪問文檔。 可以自定義 Spark 作業以獲得更細粒度的控制。 這里顯示的 Hudi 也可以與 Presto、Hive 或 Trino 集成。 定制的數量是無窮無盡的。 本文提供了有關如何使用上述工具構建基本數據管道的基本介紹!
到此這篇關于基于Apache Hudi在Google云構建數據湖平臺的文章就介紹到這了,更多相關Apache Hudi構建數據湖內容請搜索以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持!

 網公網安備
網公網安備