Python scrapy爬取蘇州二手房交易數(shù)據(jù)
使用Scrapy爬取鏈家網(wǎng)中蘇州市二手房交易數(shù)據(jù)并保存于CSV文件中要求:房屋面積、總價(jià)和單價(jià)只需要具體的數(shù)字,不需要單位名稱(chēng)。刪除字段不全的房屋數(shù)據(jù),如有的房屋朝向會(huì)顯示“暫無(wú)數(shù)據(jù)”,應(yīng)該剔除。保存到CSV文件中的數(shù)據(jù),字段要按照如下順序排列:房屋名稱(chēng),房屋戶(hù)型,建筑面積,房屋朝向,裝修情況,有無(wú)電梯,房屋總價(jià),房屋單價(jià),房屋產(chǎn)權(quán)。
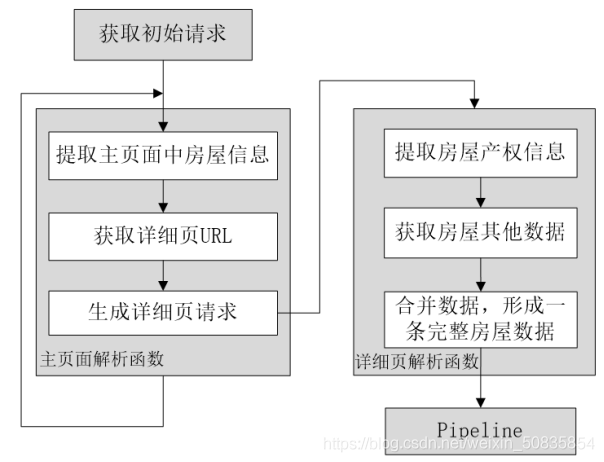
二、項(xiàng)目分析流程圖
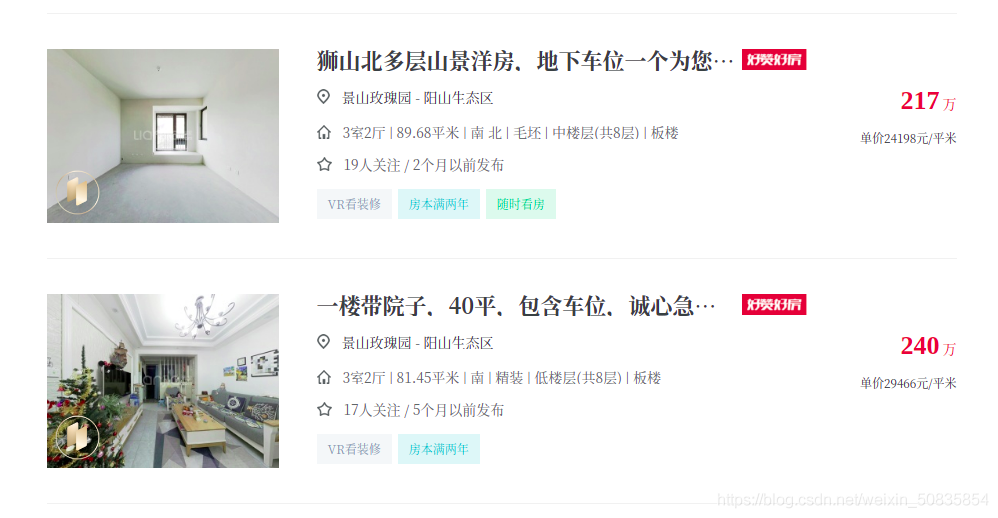

通過(guò)控制臺(tái)發(fā)現(xiàn)所有房屋信息都在一個(gè)ul中其中每一個(gè)li里存儲(chǔ)一個(gè)房屋的信息。
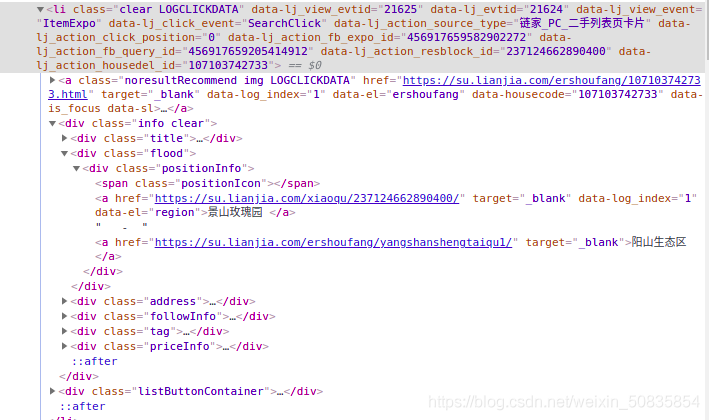
找了到需要的字段,這里以房屋名稱(chēng)為例,博主用linux截圖,沒(méi)法對(duì)圖片進(jìn)行標(biāo)注,這一段就是最中間的“景山玫瑰園” 。其他字段類(lèi)似不再一一列舉。獲取了需要的數(shù)據(jù)后發(fā)現(xiàn)沒(méi)有電梯的配備情況,所以需要到詳細(xì)頁(yè)也就是點(diǎn)擊標(biāo)題后進(jìn)入的頁(yè)面,點(diǎn)擊標(biāo)題

可以看到里面有下需要的信息。

抓取詳細(xì)頁(yè)url
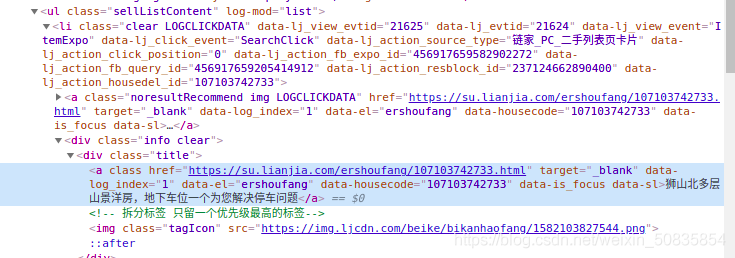
進(jìn)行詳細(xì)頁(yè)數(shù)據(jù)分析
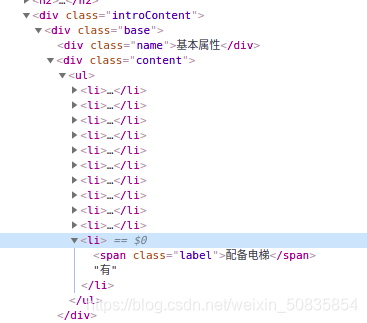
找到相應(yīng)的位置,進(jìn)行抓取數(shù)據(jù)。
三、編寫(xiě)程序創(chuàng)建項(xiàng)目,不說(shuō)了。
1.編寫(xiě)item(數(shù)據(jù)存儲(chǔ))
import scrapyclass LianjiaHomeItem(scrapy.Item): name = scrapy.Field() # 名稱(chēng) type = scrapy.Field() # 戶(hù)型 area = scrapy.Field() # 面積 direction = scrapy.Field() #朝向 fitment = scrapy.Field() # 裝修情況 elevator = scrapy.Field() # 有無(wú)電梯 total_price = scrapy.Field() # 總價(jià) unit_price = scrapy.Field() # 單價(jià)
2.編寫(xiě)spider(數(shù)據(jù)抓取)
from scrapy import Requestfrom scrapy.spiders import Spiderfrom lianjia_home.items import LianjiaHomeItemclass HomeSpider(Spider): name = 'home' current_page=1 #起始頁(yè) def start_requests(self): #初始請(qǐng)求url='https://su.lianjia.com/ershoufang/'yield Request(url=url) def parse(self, response): #解析函數(shù)list_selctor=response.xpath('//li/div[@class=’info clear’]')for one_selector in list_selctor: try:#房屋名稱(chēng)name=one_selector.xpath('//div[@class=’flood’]/div[@class=’positionInfo’]/a/text()').extract_first()#其他信息other=one_selector.xpath('//div[@class=’address’]/div[@class=’houseInfo’]/text()').extract_first()other_list=other.split('|')type=other_list[0].strip(' ')#戶(hù)型area = other_list[1].strip(' ') #面積direction=other_list[2].strip(' ') #朝向fitment=other_list[3].strip(' ') #裝修price_list=one_selector.xpath('div[@class=’priceInfo’]//span/text()')# 總價(jià)total_price=price_list[0].extract()# 單價(jià)unit_price=price_list[1].extract()item=LianjiaHomeItem()item['name']=name.strip(' ')item['type']=typeitem['area'] = areaitem['direction'] = directionitem['fitment'] = fitmentitem['total_price'] = total_priceitem['unit_price'] = unit_price #生成詳細(xì)頁(yè)url = one_selector.xpath('div[@class=’title’]/a/@href').extract_first()yield Request(url=url, meta={'item':item}, #把item作為數(shù)據(jù)v傳遞 callback=self.property_parse) #爬取詳細(xì)頁(yè) except:print('error')#獲取下一頁(yè) self.current_page+=1 if self.current_page<=100:next_url='https://su.lianjia.com/ershoufang/pg%d'%self.current_pageyield Request(url=next_url) def property_parse(self,response):#詳細(xì)頁(yè)#配備電梯elevator=response.xpath('//div[@class=’base’]/div[@class=’content’]/ul/li[last()]/text()').extract_first()item=response.meta['item']item['elevator']=elevatoryield item
3.編寫(xiě)pipelines(數(shù)據(jù)處理)
import refrom scrapy.exceptions import DropItemclass LianjiaHomePipeline:#數(shù)據(jù)的清洗 def process_item(self, item, spider):#面積item['area']=re.findall('d+.?d*',item['area'])[0] #提取數(shù)字并存儲(chǔ)#單價(jià)item['unit_price'] = re.findall('d+.?d*', item['unit_price'])[0] #提取數(shù)字并存儲(chǔ)#如果有不完全的數(shù)據(jù),則拋棄if item['direction'] =='暫無(wú)數(shù)據(jù)': raise DropItem('無(wú)數(shù)據(jù),拋棄:%s'%item)return itemclass CSVPipeline(object): file=None index=0 #csv文件行數(shù)判斷 def open_spider(self,spider): #爬蟲(chóng)開(kāi)始前,打開(kāi)csv文件self.file=open('home.csv','a',encoding='utf=8') def process_item(self, item, spider):#按要求存儲(chǔ)文件。if self.index ==0: column_name='name,type,area,direction,fitment,elevator,total_price,unit_pricen' self.file.write(column_name)#插入第一行的索引信息 self.index=1home_str=item['name']+','+item['type']+','+item['area']+','+item['direction']+','+item['fitment']+','+item['elevator']+','+item['total_price']+','+item['unit_price']+'n'self.file.write(home_str) #插入獲取的信息return item def close_soider(self,spider):#爬蟲(chóng)結(jié)束后關(guān)閉csvself.file.close()
4.編寫(xiě)settings(爬蟲(chóng)設(shè)置)
這里只寫(xiě)下需要修改的地方
USER_AGENT = ’Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36’#為裝成瀏覽器ROBOTSTXT_OBEY = False #不遵循robots協(xié)議ITEM_PIPELINES = { ’lianjia_home.pipelines.LianjiaHomePipeline’: 300, #先進(jìn)行數(shù)字提取 ’lianjia_home.pipelines.CSVPipeline’: 400 #在進(jìn)行數(shù)據(jù)的儲(chǔ)存 #執(zhí)行順序由后邊的數(shù)字決定}
這些內(nèi)容在settings有些是默認(rèn)關(guān)閉的,把用來(lái)注釋的 # 去掉即可開(kāi)啟。
5.編寫(xiě)start(代替命令行)
from scrapy import cmdlinecmdline.execute('scrapy crawl home' .split())
附上兩張結(jié)果圖。
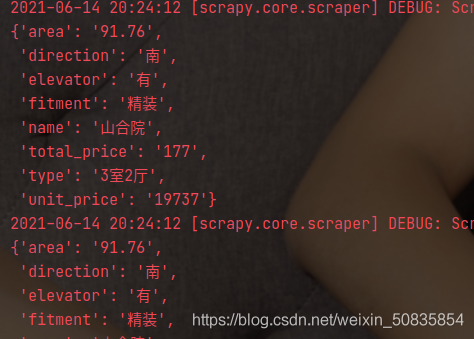
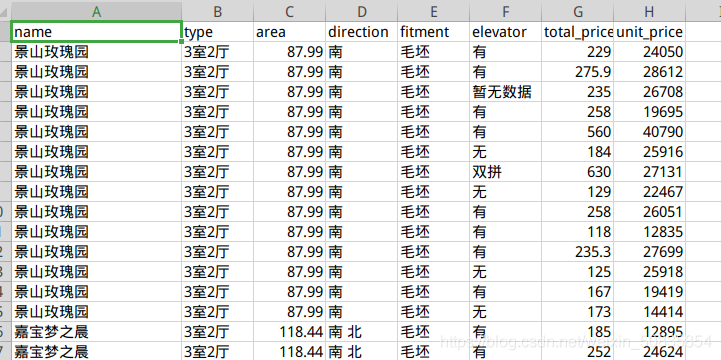
此次項(xiàng)目新增了簡(jiǎn)單的數(shù)據(jù)清洗,在整體的數(shù)據(jù)抓取上沒(méi)有增加新的難度。
到此這篇關(guān)于Python scrapy爬取蘇州二手房交易數(shù)據(jù)的文章就介紹到這了,更多相關(guān)scrapy爬取二手房交易數(shù)據(jù)內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Spring security 自定義過(guò)濾器實(shí)現(xiàn)Json參數(shù)傳遞并兼容表單參數(shù)(實(shí)例代碼)2. Java8內(nèi)存模型PermGen Metaspace實(shí)例解析3. python tkinter實(shí)現(xiàn)下載進(jìn)度條及抖音視頻去水印原理4. ASP.NET MVC使用正則表達(dá)式驗(yàn)證手機(jī)號(hào)碼5. 一文搞懂 parseInt()函數(shù)異常行為6. Python 有可能刪除 GIL 嗎?7. Python使用sftp實(shí)現(xiàn)上傳和下載功能8. python捕獲警告的三種方法9. python 統(tǒng)計(jì)list中各個(gè)元素出現(xiàn)的次數(shù)的幾種方法10. Python基于百度AI實(shí)現(xiàn)抓取表情包

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備