Python爬蟲基礎之初次使用scrapy爬蟲實例
在專門供爬蟲初學者訓練爬蟲技術的網站(http://quotes.toscrape.com)上爬取名言警句。
創建項目在開始爬取之前,必須創建一個新的Scrapy項目。進入您打算存儲代碼的目錄中,運行下列命令:
(base) λ scrapy startproject quotesNew scrapy project ’quotes ’, using template directory ’d: anaconda3libsite-packagesscrapytemp1atesproject ’, created in: D:XXXYou can start your first spider with : cd quotes scrapy genspider example example. com
首先切換到新建的爬蟲項目目錄下,也就是/quotes目錄下。然后執行創建爬蟲文件的命令:
D:XXX(master)(base) λ cd quotes D:XXXquotes (master)(base) λ scrapy genspider quotes quotes.comcannot create a spider with the same name as your project D :XXXquotes (master)(base) λ scrapy genspider quote quotes.comcreated spider ’quote’ using template ’basic’ in module:quotes.spiders.quote
該命令將會創建包含下列內容的quotes目錄:

robots協議也叫robots.txt(統一小寫)是一種存放于網站根目錄下的ASCII編碼的文本文件,它通常告訴網絡搜索引擎的網絡蜘蛛,此網站中的哪些內容是不應被搜索引擎的爬蟲獲取的,哪些是可以被爬蟲獲取的。
robots協議并不是一個規范,而只是約定俗成的。
#filename : settings.py#obey robots.txt rulesROBOTSTXT__OBEY = False分析頁面
編寫爬蟲程序之前,首先需要對待爬取的頁面進行分析,主流的瀏覽器中都帶有分析頁面的工具或插件,這里我們選用Chrome瀏覽器的開發者工具(Tools→Developer tools)分析頁面。
數據信息在Chrome瀏覽器中打開頁面http://lquotes.toscrape.com,然后選擇'Elements',查看其HTML代碼。
可以看到每一個標簽都包裹在
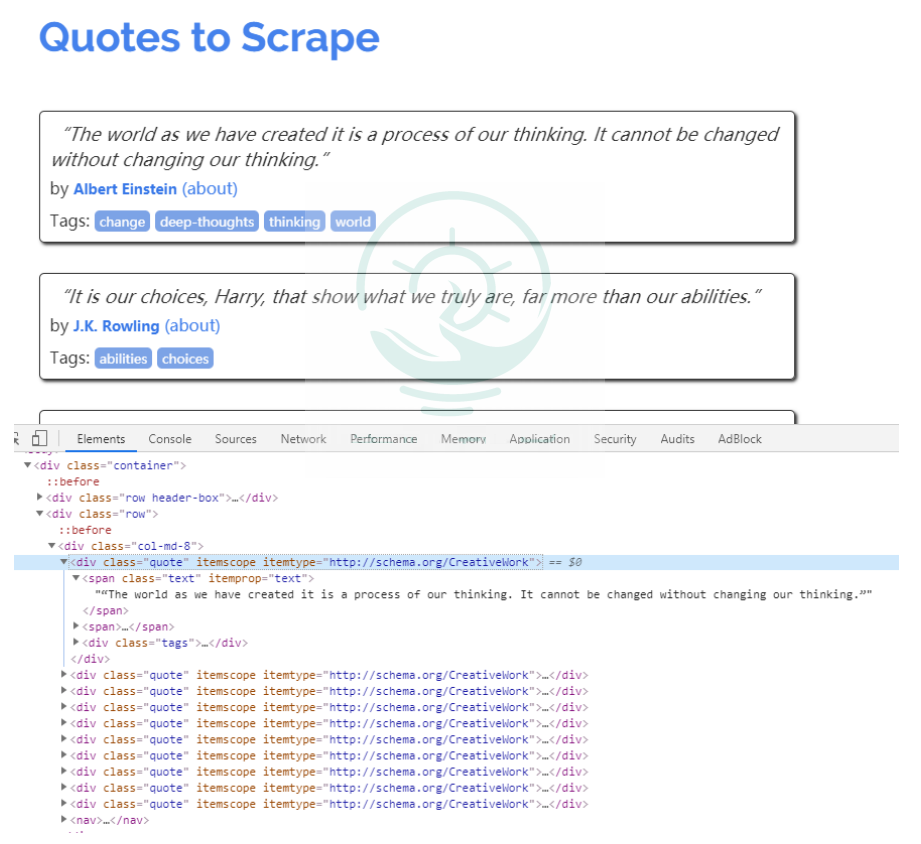
分析完頁面后,接下來編寫爬蟲。在Scrapy中編寫一個爬蟲, 在scrapy.Spider中編寫代碼Spider是用戶編寫用于從單個網站(或者-些網站)爬取數據的類。
其包含了-個用于下載的初始URL,如何跟進網頁中的鏈接以及如何分析頁面中的內容,提取生成item的方法。
為了創建一個Spider, 您必須繼承scrapy.Spider類,且定義以下三個屬性:
name:用于區別Spider。該名字必須是唯一-的, 您不可以為不同的Spider設定相同的名字。 start _urls:包含了Spider在啟動時進行爬取的ur列表。因此, 第一個被獲取到的頁面將是其中之一。后續的URL則從初始的URL獲取到的數據中提取。 parse():是spider的一一個方法。被調用時,每個初始URL完成下載后生成的Response對象將會作為唯一的參數傳遞給該函數。該方法負責解析返回的數據(response data),提取數據(生成item)以及生成需要進一步處理的URL 的Request對象。import scrapy class QuoteSpi der(scrapy . Spider): name =’quote’ allowed_ domains = [’ quotes. com ’] start_ urls = [’http://quotes . toscrape . com/’]def parse(self, response) :pass
下面對quote的實現做簡單說明。
scrapy.spider :爬蟲基類,每個其他的spider必須繼承自該類(包括Scrapy自帶的其他spider以及您自己編寫的spider)。 name是爬蟲的名字,是在genspider的時候指定的。 allowed_domains是爬蟲能抓取的域名,爬蟲只能在這個域名下抓取網頁,可以不寫。 start_ur1s是Scrapy抓取的網站,是可迭代類型,當然如果有多個網頁,列表中寫入多個網址即可,常用列表推導式的形式。 parse稱為回調函數,該方法中的response就是start_urls 網址發出請求后得到的響應。當然也可以指定其他函數來接收響應。一個頁面解析函數通常需要完成以下兩個任務:1.提取頁面中的數據(re、XPath、CSS選擇器)2.提取頁面中的鏈接,并產生對鏈接頁面的下載請求。頁面解析函數通常被實現成一個生成器函數,每一項從頁面中提取的數據以及每一個對鏈接頁面的下載請求都由yield語句提交給Scrapy引擎。
解析數據import scrapy def parse(se1f,response) : quotes = response.css(’.quote ’) for quote in quotes:text = quote.css( ’.text: :text ’ ).extract_first()auth = quote.css( ’.author : :text ’ ).extract_first()tages = quote.css(’.tags a: :text’ ).extract()yield dict(text=text,auth=auth,tages=tages)
重點:
response.css(直接使用css語法即可提取響應中的數據。 start_ur1s 中可以寫多個網址,以列表格式分割開即可。 extract()是提取css對象中的數據,提取出來以后是列表,否則是個對象。并且對于 extract_first()是提取第一個運行爬蟲在/quotes目錄下運行scrapycrawlquotes即可運行爬蟲項目。運行爬蟲之后發生了什么?
Scrapy為Spider的start_urls屬性中的每個URL創建了scrapy.Request對象,并將parse方法作為回調函數(callback)賦值給了Request。
Request對象經過調度,執行生成scrapy.http.Response對象并送回給spider parse()方法進行處理。
完成代碼后,運行爬蟲爬取數據,在shell中執行scrapy crawl <SPIDER_NAME>命令運行爬蟲’quote’,并將爬取的數據存儲到csv文件中:
(base) λ scrapy craw1 quote -o quotes.csv2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
等待爬蟲運行結束后,就會在當前目錄下生成一個quotes.csv的文件,里面的數據已csv格式存放。
-o支持保存為多種格式。保存方式也非常簡單,只要給上文件的后綴名就可以了。(csv、json、pickle等)
到此這篇關于Python爬蟲基礎之初次使用scrapy爬蟲實例的文章就介紹到這了,更多相關Python scrapy框架內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備