Spring Cloud 專題之Sleuth 服務跟蹤實現(xiàn)方法
在一個微服務架構(gòu)中,系統(tǒng)的規(guī)模往往會比較大,各微服務之間的調(diào)用關(guān)系也錯綜復雜。通常一個有客戶端發(fā)起的請求在后端系統(tǒng)中會經(jīng)過多個不同的微服務調(diào)用阿里協(xié)同產(chǎn)生最后的請求結(jié)果。在復雜的微服務架構(gòu)中,幾乎每一個前端請求都會形成一條復雜的分布式的服務調(diào)用鏈路,在每條鏈路中任何一個依賴服務出現(xiàn)延遲過高或錯誤的時候都有可能引起請求最后的失敗。
這個時候,對于每個請求,全鏈路調(diào)用的跟蹤就邊得越來越重要,通過實現(xiàn)對請求調(diào)用的跟蹤可以幫助我們快速發(fā)現(xiàn)問題根源以及監(jiān)控分析每條請求鏈路上的性能瓶頸等。而Spring Cloud Sleuth就是一個提供了一套完整的解決方案的組件。
在開始今天的這個例子之前,可以看一下我之前的幾篇博客,特別是hystrix之前的博客。本篇博客就是在這基礎(chǔ)上所增加的新功能。在之前的實踐中,通過9004的customer-server項目調(diào)用9003的hello-server項目的接口。
準備工作在之前的服務調(diào)用的方法上加上日志操作。
customer-server的CustomerController類:
@RequestMapping('/sayHello1')@ResponseBodypublic String invokeSayHello1(String name){ logger.info('調(diào)用了customer-server的sayHello1方法,參數(shù)為:{}',name); return serivce.invokeSayHello1(name);}
hello-server的Hello1Controller類:
@RequestMapping('/sayHello1')public String sayHello1(@RequestParam('name') String name){ logger.info('你好,服務名:{},端口為:{},接收到的參數(shù)為:{}',instanceName,host,name); try {int sleepTime = new Random().nextInt(3000); logger.error('讓線程阻塞 {} 毫秒',sleepTime);Thread.sleep(sleepTime); } catch (InterruptedException e) {e.printStackTrace(); } return '你好,服務名:'+instanceName+',端口為:'+host+',接收到的參數(shù)為:'+name;}
在頁面上訪問localhost:9004/sayHello1?name=charon
# customer-server中的打印日志2021-08-09 23:22:33.905 INFO 19776 --- [nio-9004-exec-8] c.c.e.controller.CustomerController : 調(diào)用了customer-server的sayHello1方法,參數(shù)為:charon# hello-server中的打印日志2021-08-09 23:22:33.917 INFO 2884 --- [nio-9003-exec-9] c.c.e.controller.Hello1Controller: 你好,服務名:hello-server,端口為:9003,接收到的參數(shù)為:charon實現(xiàn)跟蹤
在修改完上面的代碼后,為customer-server項目和hello-server項目添加服務跟蹤的功能,引入依賴
<!--引入sleuth鏈路追蹤的jar包--><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId></dependency>
頁面調(diào)用查看日志:
# customer-server中的打印日志2021-08-09 23:30:44.782 INFO [customer-server,0e307552774ef605,0e307552774ef605,true] 14616 --- [nio-9004-exec-2] c.c.e.controller.CustomerController : 調(diào)用了customer-server的sayHello1方法,參數(shù)為:charon# hello-server中的打印日志2021-08-09 23:30:44.807 INFO [hello-server,0e307552774ef605,4cf4d9dd57ca7478,true] 6660 --- [nio-9003-exec-2] c.c.e.controller.Hello1Controller: 你好,服務名:hello-server,端口為:9003,接收到的參數(shù)為:charon
從上面的控制臺的輸出內(nèi)容可以看到形如[customer-server,0e307552774ef605,0e307552774ef605,true] 的日志信息,而浙西而元素正是實現(xiàn)分布式服務跟蹤的重要組成部分,每個值的含義如下:
customer-server:應用的名稱,也就是application.properties中的soring。application.name的值 0e307552774ef605:Spring Cloud Sleuth生成的一個ID,成微Trace ID,它用來標識一條請求鏈路,一條請求鏈路中包含一個Trace ID,多個Span ID。 0e307552774ef605:Spring Cloud Sleuth生成的另一個ID,成為Span ID,它表識一個基本的工作單元,比如發(fā)慫一個HTTP請求 true:表示是否要將改信息輸出到Zipkin等服務中來收集和展示在一個服務請求鏈路的調(diào)用過程中,會包吃并傳遞同一個Trace ID,從而將整個分布于不容微服務進程中的請求跟蹤信息串聯(lián)起來。以上面輸出內(nèi)容為例,customer-server和hello-server同屬于一個前端服務請求來源,所以他們的Trace ID是相同的,處于同一個請求鏈路中。通過Trace ID,我們就能將所有請求過程的日志關(guān)聯(lián)起來。
在Spring Boot應用中,通過引入spring-cloud-starter-sleuth依賴之后,他會自動為當前應用構(gòu)建起通道跟蹤機制,比如:
通過RabbitMQ,Kafka等中間件傳遞的請求 通過Zuul代理傳遞的請求 通過RestTemplate發(fā)起的請求。抽樣收集通過TraceID和SpanID已經(jīng)實現(xiàn)了對分布式系統(tǒng)中的請求跟蹤,而記錄的跟蹤信息最終會被分析系統(tǒng)收集起來,并用來實現(xiàn)對分布式系統(tǒng)的監(jiān)控和分析功能。
理論上講,收集的跟蹤信息越多就可以越好的反應系統(tǒng)的真實運行情況,并給出更精準的預警和分析,但是在高并發(fā)的分布式系統(tǒng)運行時,大兩的請求調(diào)用會產(chǎn)生海量的跟蹤日志信息,如果收集過多對整個系統(tǒng)的性能也會造成一定的影響,同時保存大兩的日志信息也需要很大的存儲開銷。所以在Sleuth中菜用了抽樣收集的方式來為跟蹤信息打商收集標記。也就是我們之前在日志信息中看到的第4個布爾類型的值,它代表了改信息是否要改后續(xù)的跟蹤信息收集器獲取或存儲。
默認情況下,Sleuth會使用 zipkin brave的ProbabilityBasedSampler的抽樣策略(現(xiàn)在已經(jīng)不推薦使用),即以請求百分比的方式配置和收集跟蹤信息,我們可以在配置文件中配置參數(shù)對其百分比值進行設(shè)置(它的默認值為 0.1,代表收集 10% 的請求跟蹤信息)。
spring.sleuth.sampler.probability=0.5
而如果在配置文件中配置了 spring.sleuth.sampler.rate 的屬性值,那么便會使用zipkin Brave自帶的RateLimitingSampler的抽樣策略。不同于ProbabilityBasedSampler菜用概況收集的策略,RateLimitingSampler是菜用的限速收集,也就是說它可以用來限制每秒跟蹤請求的最大數(shù)量。
如果同時設(shè)置了 spring.sleuth.sampler.rate 和 spring.sleuth.sampler.probability 屬性值,也仍然使用 RateLimitingSampler 抽樣策略(即 spring.sleuth.sampler.probability 屬性值無效) RateLimitingSampler 策略每秒間隔接受的 trace 量設(shè)置范圍:最小數(shù)字為 0,最大值為 2,147,483,647(最大 int)整合ZipkinZipkin是twitter的一個開源項目,它基于Google Dapper實現(xiàn),我們可以用它來實現(xiàn)收集各個服務器上的請求鏈路的跟蹤。并通過它提供的REST API接口來輔助查詢跟蹤數(shù)據(jù)以實現(xiàn)對分布式系統(tǒng)的監(jiān)控程序,從而及時發(fā)現(xiàn)系統(tǒng)中出現(xiàn)的延遲升高問題并找出系統(tǒng)性能瓶頸的根源。同時,Zipkin還提供了方便的UI組件來幫助我們直觀地所搜跟蹤信息和分析請求地鏈路明細,比如可以查詢某段時間內(nèi)各用戶請求地處理時間等。
Spring Boot 2.x 以后官網(wǎng)不推薦使用源碼方式編譯,推薦使用官網(wǎng)編譯好的jar執(zhí)行。所以我們不熟Zipkin也使用jar包的方式。
1.下載Zipkin我這里是到maven倉庫中下載的。
https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec
下載完成后,使用java -jar命令啟動zipkin。
為customer-server和hello-server的項目引入zipkin的包:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin</artifactId></dependency>
配置文件添加zipkin的地址:
spring.zipkin.base-url=http://localhost:94113.測試與分析
完成所有接入Zipkin的工作后,依次講服務起來,瀏覽器發(fā)送請求做測試。
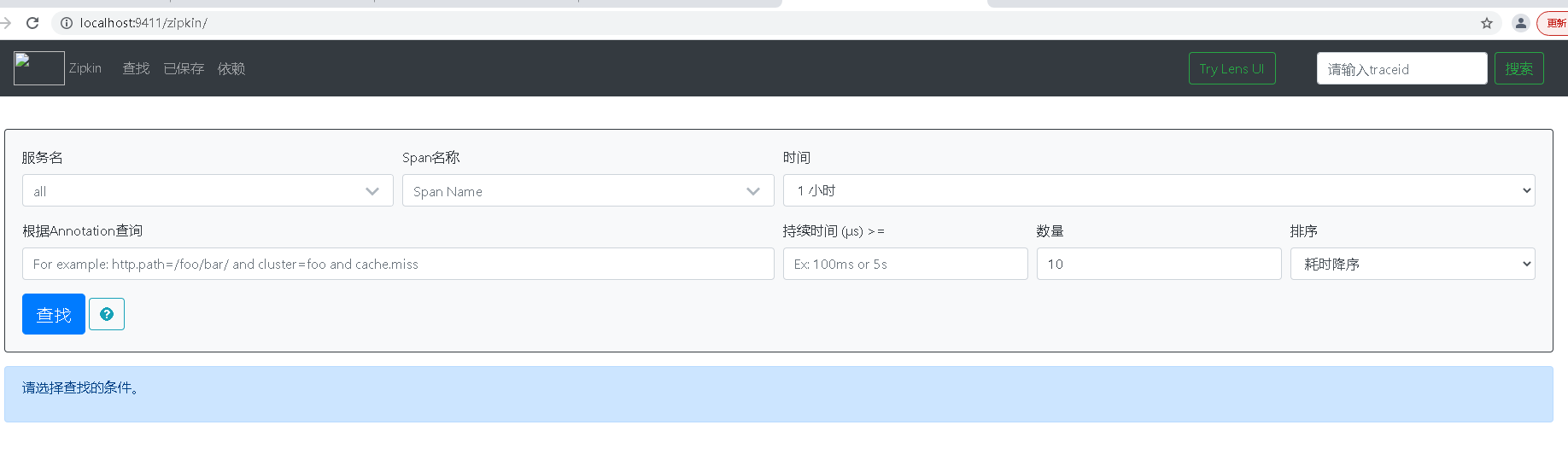
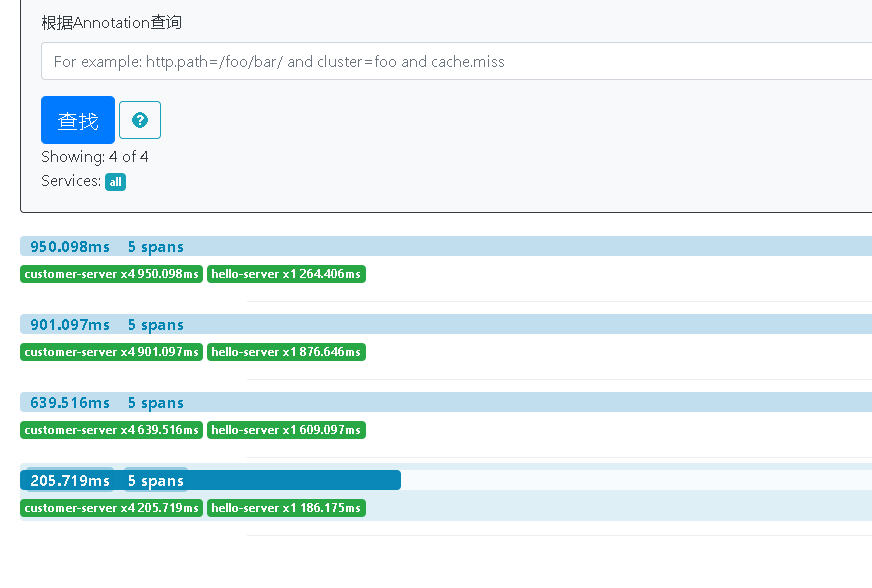
點擊查找按鈕,下方出現(xiàn)服務調(diào)用的信息。注意,只有在sleuth的最后一個參數(shù)為true的時候,才會講改跟蹤信息輸出給Zipkin Server。
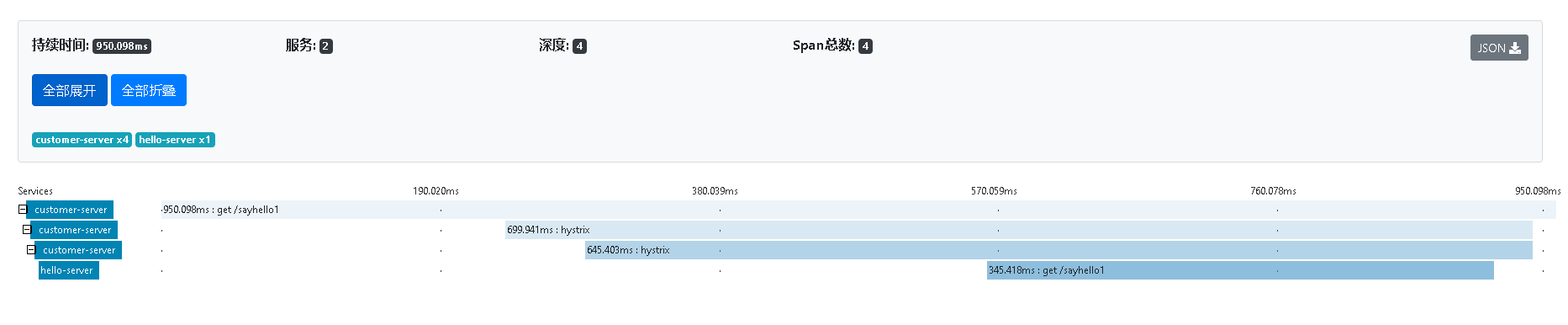
單擊其中的某一個,還可以得到Sleuth跟蹤到的詳細信息。其中就包括時間請求時間消耗等。
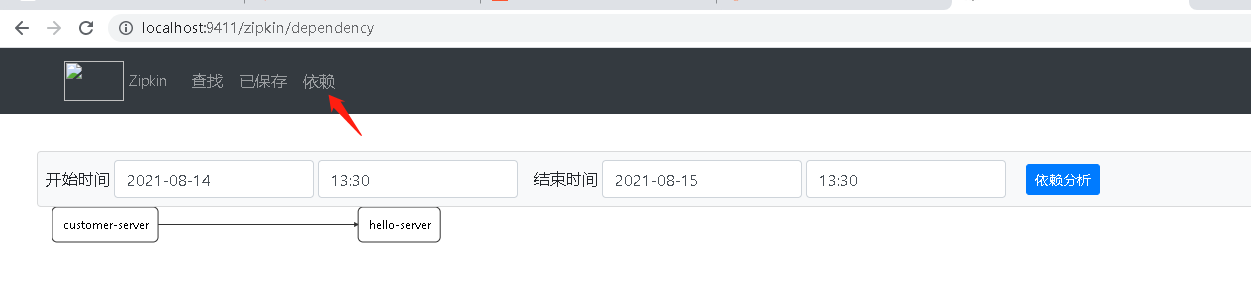
單擊導航欄中的依賴按鈕,還可以查看到Zipkin根據(jù)跟蹤信息分析生成的系統(tǒng)關(guān)系請求鏈路依賴關(guān)系圖。
在SpringBoot2.0之前的版本,Zipkin-Server端由我們自己創(chuàng)建項目來搭建。可以比較靈活的選擇數(shù)據(jù)持久化的配置,SpringBoot2.0之后的版本,Zipkin-Server端由官方提供,無需我們自己搭建,那么如何選擇去配置將數(shù)據(jù)持久化到MySQL呢?
1.創(chuàng)建zipkin數(shù)據(jù)庫在下載好的zipkin-serve的jar包中,找到zipkin-server-shared.yml的文件,

在里面可以找到關(guān)于mysql的持久化配置,可以看到數(shù)據(jù)庫名稱默認為zipkin,
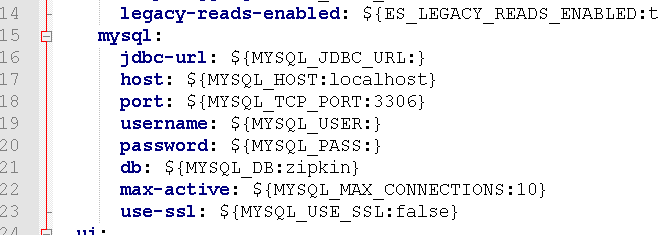
初始化mysql的腳本:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
創(chuàng)建的數(shù)據(jù)庫如下:
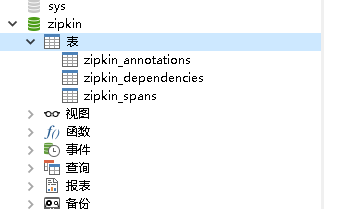
在啟動zipkin的時候,以命令行的方式啟動,輸入mysql的參數(shù)
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root3.測試與分析
瀏覽器訪問,因為我這次調(diào)用服務超時了,觸發(fā)了hystrix的斷路器功能,所以這次有8個span。
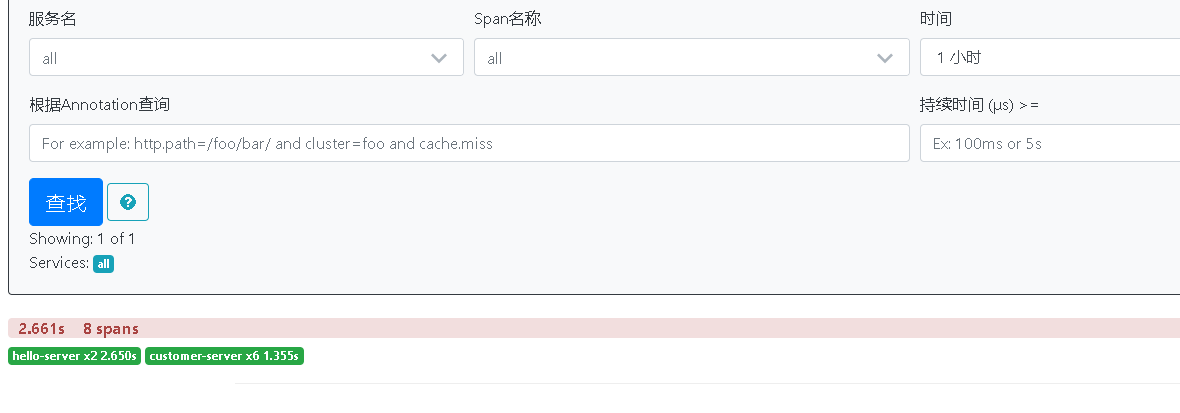
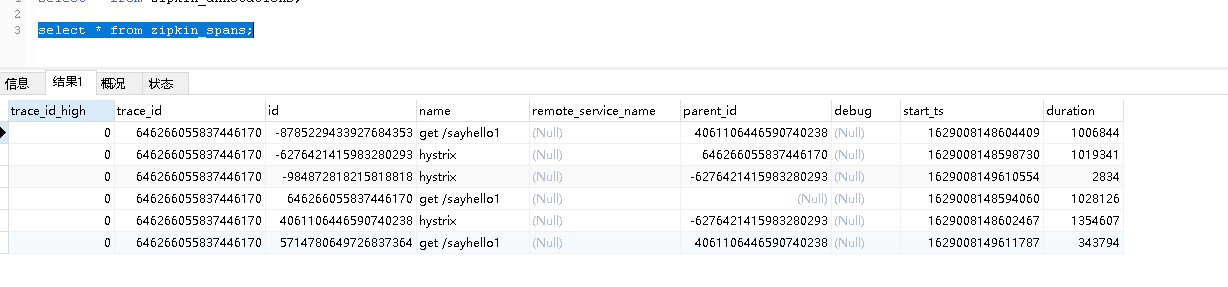
關(guān)閉zipkin-server,然后重啟,發(fā)現(xiàn)依然能夠查詢到上一次請求的服務鏈路跟蹤數(shù)據(jù)。查看數(shù)據(jù)庫表,發(fā)現(xiàn)數(shù)據(jù)都存儲到表里了。
參考文章:
翟永超老師的《Spring Cloud微服務實戰(zhàn)》
https://www.hangge.com/blog/cache/detail_2803.html
https://blog.csdn.net/Thinkingcao/article/details/104957540
到此這篇關(guān)于Spring Cloud 專題之Sleuth 服務跟蹤的文章就介紹到這了,更多相關(guān)Spring Cloud Sleuth 服務跟蹤內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備