python使用requests庫(kù)爬取拉勾網(wǎng)招聘信息的實(shí)現(xiàn)
按F12打開開發(fā)者工具抓包,可以定位到招聘信息的接口
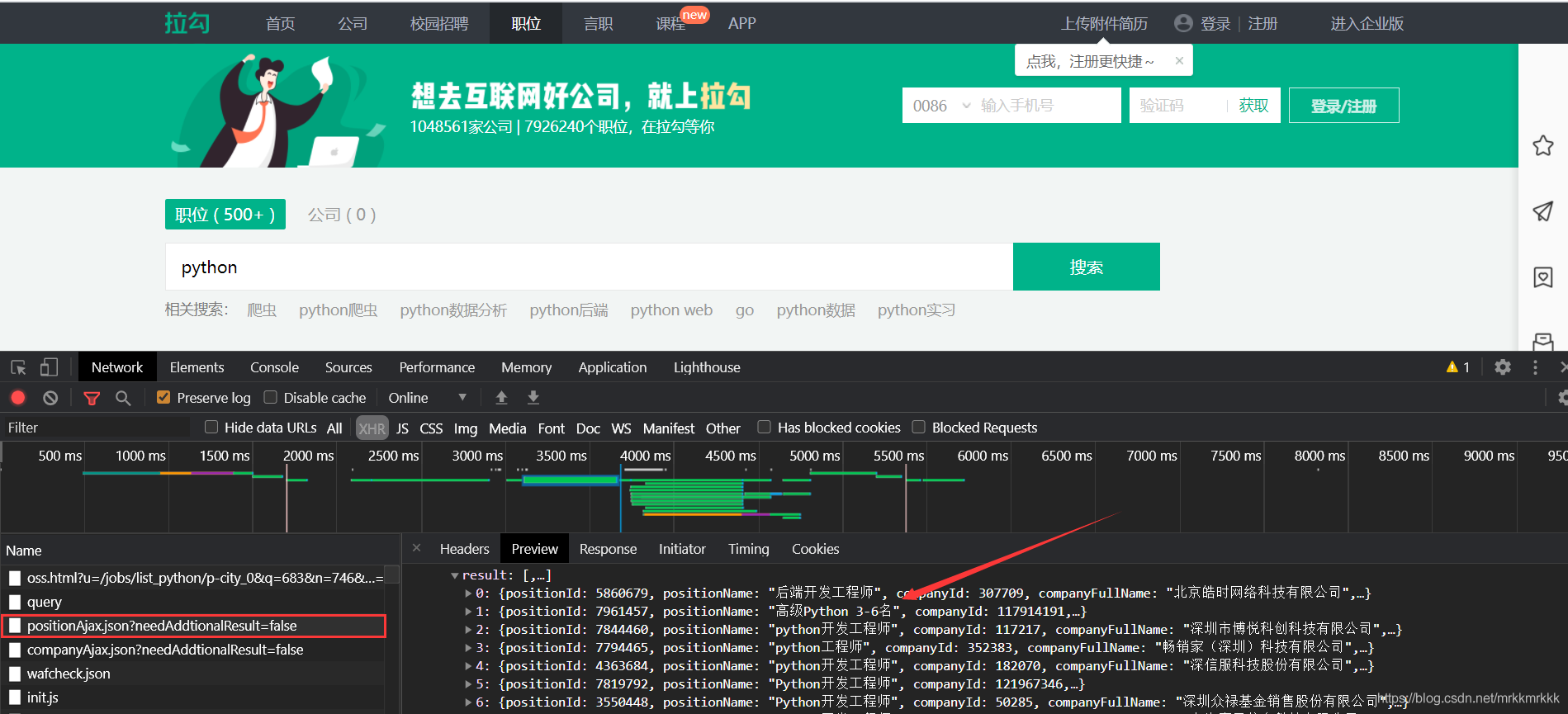
在請(qǐng)求中可以獲取到接口的url和formdata,表單中pn為請(qǐng)求的頁數(shù),kd為關(guān)請(qǐng)求職位的關(guān)鍵字
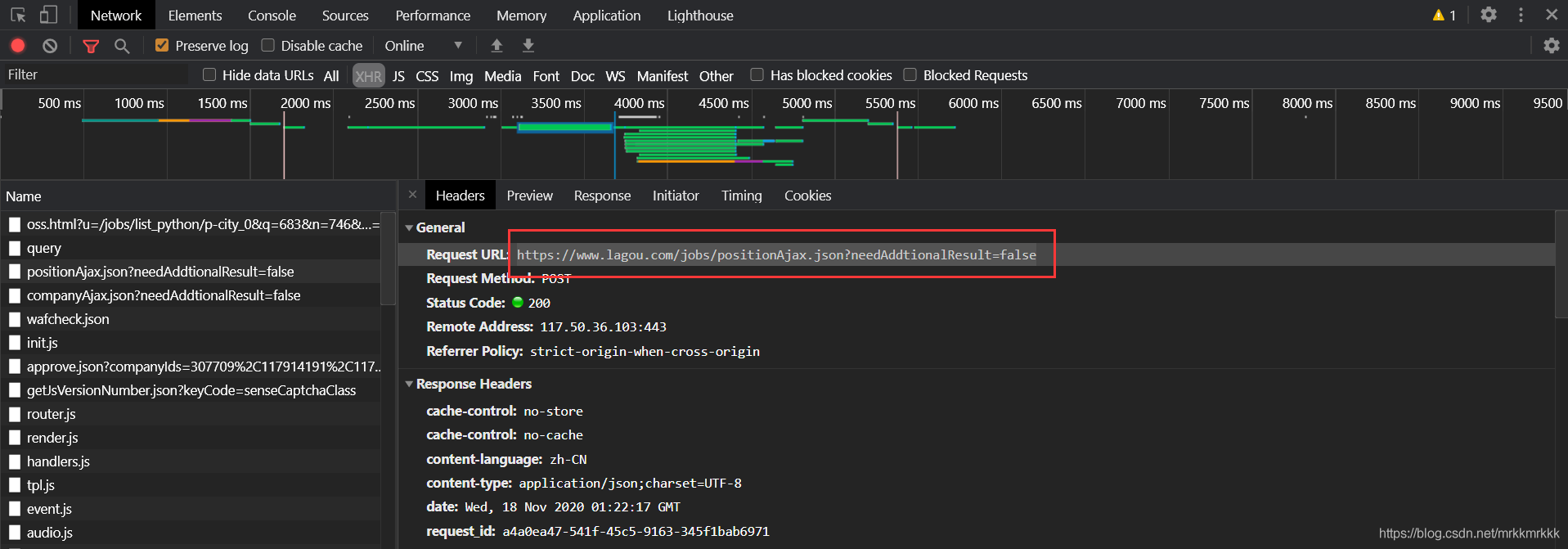
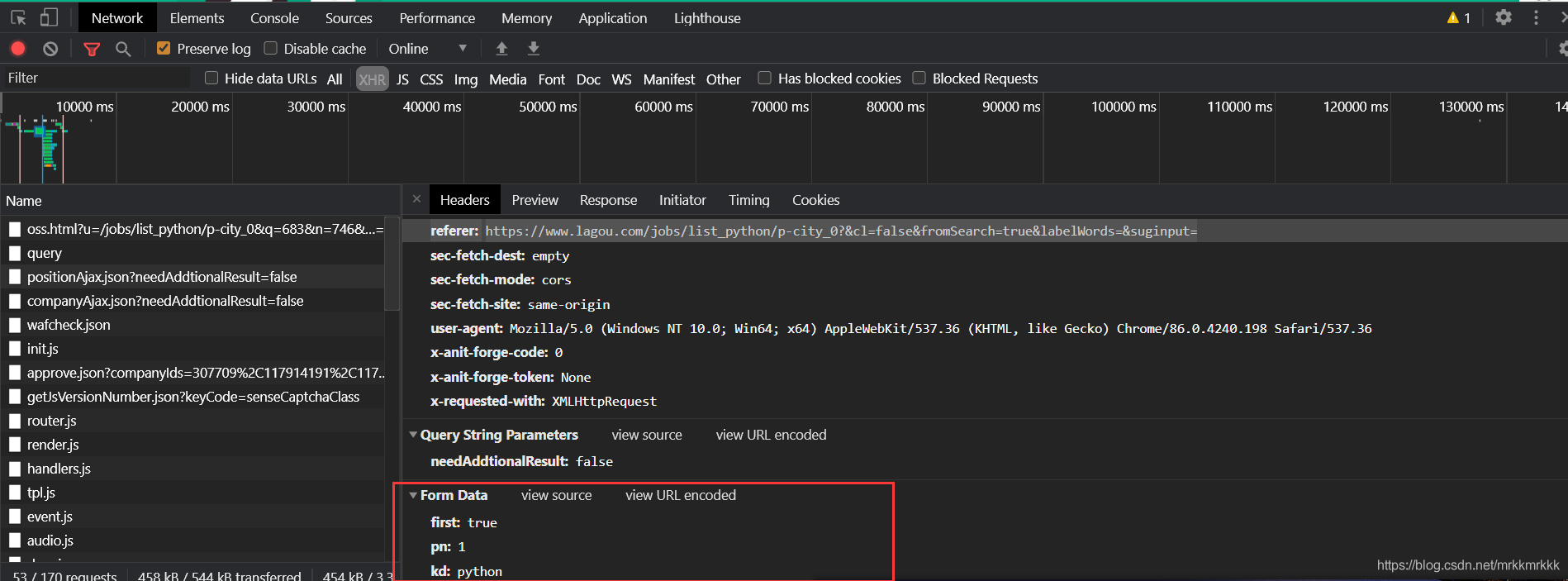
使用python構(gòu)建post請(qǐng)求
data = { ’first’: ’true’, ’pn’: ’1’, ’kd’: ’python’}headers = { ’referer’: ’https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=’, ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’}res = requests.post('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false', data=data,headers=headers)print(res.text)
發(fā)現(xiàn)沒有從接口獲取到數(shù)據(jù)

換了個(gè)網(wǎng)絡(luò)后接口還是會(huì)返回操作頻繁的錯(cuò)誤信息,仔細(xì)檢查后發(fā)現(xiàn)這個(gè)接口需要一個(gè)動(dòng)態(tài)的cookies不然會(huì)一值返回錯(cuò)誤頻繁
data = { ’first’: ’true’, ’pn’: ’1’, ’kd’: ’python’}#頭部中必須有user-agent和referer不然不會(huì)返回cookiesheaders = { ’referer’: ’https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=’, ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’}#通過訪問主頁獲取cookiesr1= requests.get('https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=’',headers=headers)#再post請(qǐng)求中傳入cookiesr2 = requests.post('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false', data=data,headers=headers, cookies=r2.cookies)print(r2.text)
注意!每請(qǐng)求十次接口cookies也會(huì)刷新一次,下面貼上完整爬蟲代碼
import jsonimport loggingimport requests#獲取cookiedef getCookie(): res = requests.get('https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',headers=headers) return res.cookies#獲取json數(shù)據(jù)def getPage(i, cookies, kw): data = { ’first’: ’true’, ’pn’: i, ’kd’: kw } res = requests.post('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false', data=data, headers=headers, cookies=cookies) return json.loads(res.text)#合并列表def reduceList(l): text = '' for i in l: text += i + ' ' return text.strip()#提取字段并保存到文件中def saveInCsv(f, data): js = data['content']['positionResult']['result'] for node in js: # 對(duì)空值進(jìn)行處理 district = node['district'] if district != None: district = '-' + district else: district = '' f.write( node['positionName'] + '·' + node['city'] + district + '·' + node['salary'] + '·' + node['workYear'] + '·' + node['education'] + '·' + reduceList(node['skillLables']) + '·' + node['companyShortName'] + '·' + node['companySize'] + '·' + node['positionAdvantage'] + 'n')if __name__ == ’__main__’: #定義頭部 headers = { ’referer’: ’https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=’, ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’ } #初始化cookie cookies = getCookie() with open('file.csv', 'w', encoding='utf-8') as f: for i in range(1, 31): #每十個(gè)請(qǐng)求重新獲取cookie if (i % 10 == 0):cookies = getCookie() #解析字段并存儲(chǔ) data = getPage(i, cookies, 'python') saveInCsv(f, data)
到此這篇關(guān)于python使用requests庫(kù)爬取拉勾網(wǎng)招聘信息的實(shí)現(xiàn)的文章就介紹到這了,更多相關(guān)python requests爬取拉勾網(wǎng)內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. vue3+ts+elementPLus實(shí)現(xiàn)v-preview指令2. Xml簡(jiǎn)介_動(dòng)力節(jié)點(diǎn)Java學(xué)院整理3. 使用Hangfire+.NET 6實(shí)現(xiàn)定時(shí)任務(wù)管理(推薦)4. 如何在jsp界面中插入圖片5. phpstudy apache開啟ssi使用詳解6. jsp實(shí)現(xiàn)登錄驗(yàn)證的過濾器7. jsp文件下載功能實(shí)現(xiàn)代碼8. 詳解瀏覽器的緩存機(jī)制9. 爬取今日頭條Ajax請(qǐng)求10. xml中的空格之完全解說
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備