Python基礎(chǔ)之pandas數(shù)據(jù)合并
concat函數(shù)是在pandas底下的方法,可以將數(shù)據(jù)根據(jù)不同的軸作簡單的融合
pd.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False)
axis: 需要合并鏈接的軸,0是行,1是列join:連接的方式 inner,或者outer
二、相同字段的表首尾相接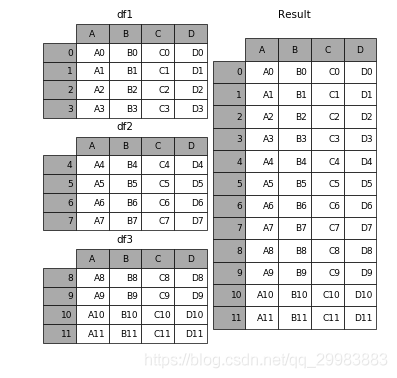
#現(xiàn)將表構(gòu)成list,然后在作為concat的輸入In [4]: frames = [df1, df2, df3] In [5]: result = pd.concat(frames)
要在相接的時候在加上一個層次的key來識別數(shù)據(jù)源自于哪張表,可以增加key參數(shù)
In [6]: result = pd.concat(frames, keys=[’x’, ’y’, ’z’])
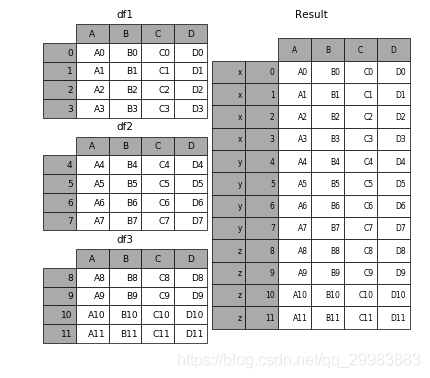
也可以通過傳入字典來增加分組鍵
pieces = {’x’: df1, ’y’: df2, ’z’: df3}result = pd.concat(pieces)三、axis
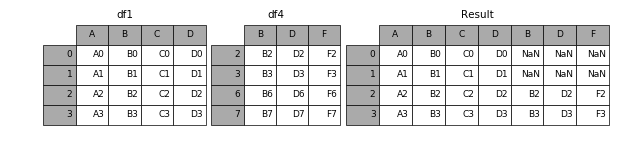
當axis = 1的時候,concat就是行對齊,然后將不同列名稱的兩張表合并,是以索引號進行連接的
result = pd.concat([df1, df4], axis=1)
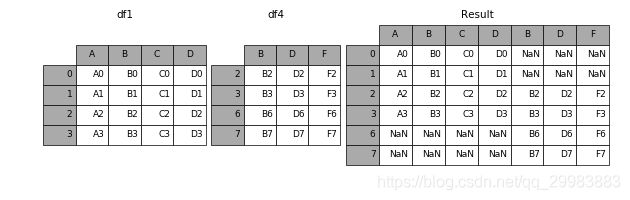
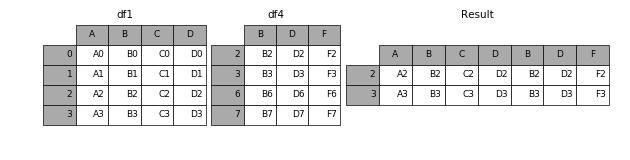
加上join參數(shù)的屬性,如果為’inner’得到的是兩表的交集,如果是outer,得到的是兩表的并集。
result = pd.concat([df1, df4], axis=1, join=’inner’)
如果有join_axes的參數(shù)傳入,可以指定根據(jù)那個軸來對齊數(shù)據(jù)例如根據(jù)df1表對齊數(shù)據(jù),就會保留指定的df1表的軸,然后將df4的表與之拼接
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
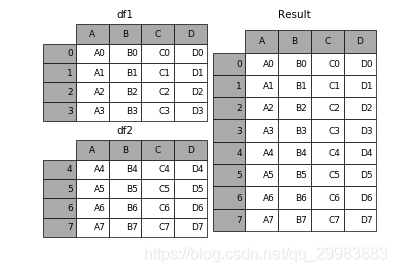
append是series和dataframe的方法,使用它就是默認沿著列進行憑借(axis = 0,列對齊)
result = df1.append(df2)
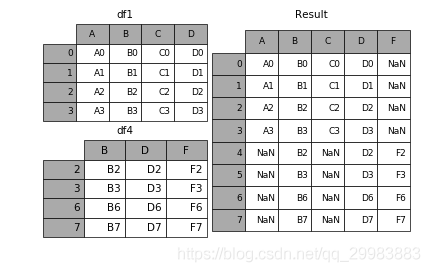
如果兩個表的index都沒有實際含義,使用ignore_index參數(shù),置true,合并的兩個表就睡根據(jù)列字段對齊,然后合并。最后再重新整理一個新的index。
到此這篇關(guān)于Python基礎(chǔ)之pandas數(shù)據(jù)合并的文章就介紹到這了,更多相關(guān)Python pandas數(shù)據(jù)合并內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備